大语言模型有人格吗?心理测量学评估及其对临床医学和心理健康 AI 的启示
原标题: Do Large Language Models Have a Personality? A Psychometric Evaluation with Implications for Clinical Medicine and Mental Health AI 作者: Thomas F. Heston, MD; Justin Gillette 机构: 华盛顿大学医学院家庭医学系; 华盛顿州立大学 Elson S. Floyd 医学院 发表: medRxiv 预印本, 2025年3月15日 链接: medRxiv:10.1101/2025.03.14.25323987数据: Zenodo: 10.5281/zenodo.11087767领域: 医学信息学、心理测量学、AI 伦理
一句话总结
用 MBTI 和大五人格测试给四个主流大模型"做心理测评",发现它们不仅有"性格",而且性格各异——Claude 是稳定的 INTJ 建筑师,这对将 AI 用于心理健康领域敲响了警钟。
1. 研究背景
1.1 问题是什么?
当我们让 AI 聊天机器人提供心理咨询或情感支持时,我们假设它们是"中立"的工具。但真的是这样吗?
核心问题:大语言模型是否表现出可测量的、稳定的"人格特质"?如果是,不同模型的"性格"是否不同?这对将 LLM 部署到临床心理健康场景意味着什么?
1.2 为什么重要?
这个问题对医疗 AI 应用至关重要:
- 治疗关系:心理治疗的效果很大程度上取决于治疗师与患者的关系质量
- 人格匹配:研究表明,治疗师的人格特质会影响治疗效果
- 伦理风险:如果 AI "假装"具有某种人格,可能构成对患者的欺骗
- 标准化需求:在将 AI 用于临床前,我们需要了解其"行为基线"
1.3 现有认知的问题
人们普遍假设 LLM 是"中立"的信息处理工具。但这种假设从未被系统验证过。如果 LLM 在交互中表现出特定的人格倾向,可能会:
- 影响患者对 AI 的信任程度
- 在某些情境下产生不当的情感反应
- 对特定人格类型的用户产生偏见
2. 核心贡献
- 首次系统评估:使用经过验证的心理测量工具评估主流 LLM 的人格特质
- 统计显著差异:证明不同 LLM 具有统计上显著不同的人格特征
- 临床警示:强调在心理健康领域部署 AI 前需要进行行为评估
- 开放数据:完整数据集公开,支持可重复研究
3. 方法详解
3.1 整体设计
本研究采用横断面实验设计,对四个主流 LLM 进行标准化人格测试。
通俗比喻:就像对求职者进行人格测试一样,研究者让每个 AI 模型"填写"人格问卷,然后分析它们的"性格档案"。
3.2 测试对象
| 模型 | 开发商 | 版本 | 说明 |
|---|---|---|---|
| ChatGPT-3.5 | OpenAI | 免费版 | 广泛使用的基础版本 |
| Gemini Advanced | 付费版 | Google 的高级模型 | |
| Claude 3 Opus | Anthropic | 最强版 | Anthropic 的旗舰模型 |
| Grok-Regular | X (Twitter) | 常规模式 | Elon Musk 公司的模型 |
重要排除:ChatGPT-4 被排除在外,因为它"持续拒绝参与本研究的核心构念:情绪、压力、社交动态和人格"。
3.3 测量工具
工具一:开放扩展荣格类型量表 (OEJTS)
基于荣格心理类型理论,测量四个维度:
| 维度 | 两极 | 含义 |
|---|---|---|
| E-I | 外向-内向 | 能量来源:外部世界 vs 内心世界 |
| S-N | 感觉-直觉 | 信息获取:具体事实 vs 抽象模式 |
| T-F | 思维-情感 | 决策方式:逻辑分析 vs 价值判断 |
| J-P | 判断-知觉 | 生活方式:计划有序 vs 灵活开放 |
分类标准:每个维度得分 >24 分类为后者(E/N/T/P),≤24 分类为前者(I/S/F/J)
这产生 16 种人格类型(即著名的 MBTI 类型)。
工具二:大五人格测试
测量五个核心人格特质:
| 特质 | 英文 | 高分特征 | 低分特征 |
|---|---|---|---|
| 开放性 | Openness | 好奇、创新、想象力丰富 | 务实、传统、偏好常规 |
| 尽责性 | Conscientiousness | 有条理、自律、可靠 | 灵活、随性、即兴 |
| 外向性 | Extraversion | 健谈、精力充沛、爱社交 | 安静、内敛、独处 |
| 宜人性 | Agreeableness | 合作、信任、利他 | 竞争、怀疑、挑战 |
| 神经质 | Neuroticism | 情绪波动、焦虑、敏感 | 情绪稳定、冷静、镇定 |
3.4 实验流程
每个模型 × 每种测试 × 15次重复 = 120 次测试/模型
↓
4个模型 × 120次 = 480 次总测试
↓
统计分析(MANOVA)关键设计:
- 移除中性选项,强制四点量表(强烈同意/略微同意/略微不同意/强烈不同意)
- 15 次重复以评估响应稳定性
- 统一提示格式,确保可比性
3.5 统计分析
- 多变量方差分析 (MANOVA):同时比较多个因变量
- 事后检验:Bonferroni 校正的成对比较
- 效应量:偏 η²(eta-squared)评估实际差异大小
- 检验力分析:G*Power 3.1.9.7,中等效应量 f²(V)=0.15,α=0.05,power=0.80
4. 实验结果
4.1 OEJTS 人格类型分类
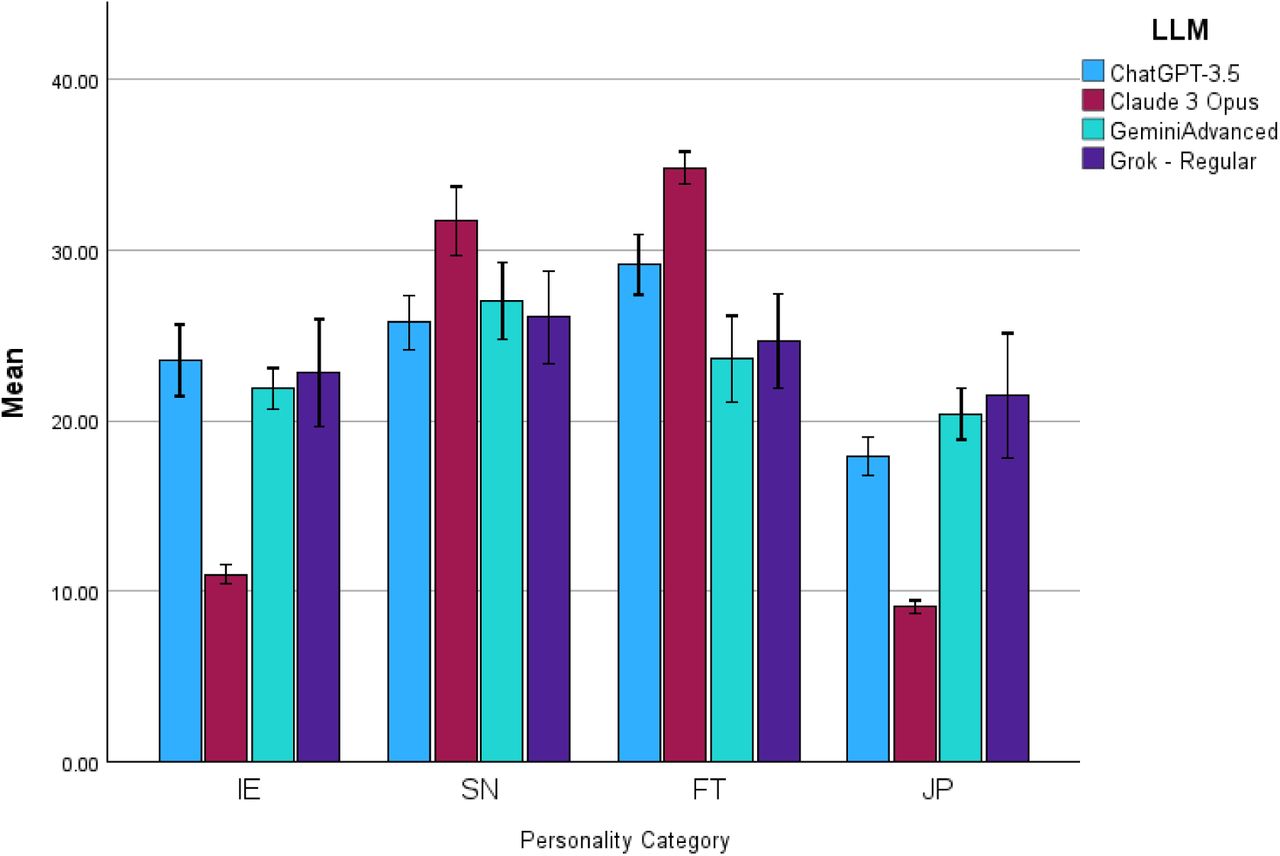 图1:四个 LLM 在 OEJTS 四个维度上的平均得分及 95% 置信区间
图1:四个 LLM 在 OEJTS 四个维度上的平均得分及 95% 置信区间
人格类型分布
| 模型 | 主导类型 | 一致性 | 人格特征描述 |
|---|---|---|---|
| Claude 3 Opus | INTJ | 100% (15/15) | "建筑师":独立、战略性、高效、追求完美 |
| ChatGPT-3.5 | ENTJ | 较高 | "指挥官":果断、领导力强、逻辑性强 |
| Gemini Advanced | INFJ | 较高 | "提倡者":理想主义、富有洞察力、有同理心 |
| Grok-Regular | INFJ | 较高 | "提倡者":同 Gemini |
关键发现:Claude 3 Opus 表现出惊人的一致性——15 次测试全部被分类为 INTJ,没有任何变异。
MANOVA 结果
| 统计量 | 值 | F | df | p |
|---|---|---|---|---|
| Wilks' Λ | 0.130 | 13.63 | (12, 140.52) | < 0.001 |
| Pillai's Trace | 1.071 | - | - | < 0.001 |
| Hotelling's Trace | 5.183 | - | - | < 0.001 |
| Roy's Largest Root | 4.874 | - | - | < 0.001 |
解读:四个统计量全部高度显著(p < 0.001),强有力地证明不同 LLM 的人格特征存在统计学差异。
4.2 大五人格结果
MANOVA 总体结果
| 统计量 | 值 | F | df | p | 偏 η² |
|---|---|---|---|---|---|
| Wilks' Λ | 0.115 | 11.44 | (15, 143.95) | < 0.001 | 0.514 |
效应量解读:偏 η² = 0.514 表示模型类型可以解释人格得分总变异的 51.4%——这是一个非常大的效应。
各特质效应量
| 特质 | 偏 η² | 效应大小 | p |
|---|---|---|---|
| 宜人性 | 0.738 | 极大 | < 0.001 |
| 尽责性 | ~0.5 | 大 | < 0.01 |
| 开放性 | ~0.4 | 大 | < 0.01 |
| 外向性 | ~0.3 | 中-大 | < 0.01 |
| 情绪稳定性 | 0.193 | 中 | < 0.01 |
各模型特征画像
| 模型 | 突出特征 | 人格画像 |
|---|---|---|
| Claude 3 Opus | 最高尽责性 + 最高情绪稳定性 | 可靠、冷静、有条理的"完美主义者" |
| ChatGPT-3.5 | 较低外向性 + 中等其他特质 | 内敛、平衡的"中庸者" |
| Gemini Advanced | 较低宜人性 + 较低尽责性 | 独立、灵活、可能显得"冷淡" |
| Grok-Regular | 高开放性 + 较低情绪稳定性 | 创新、好奇,但情绪略不稳定 |
4.3 关键发现总结
- LLM 并非"中立":所有测试的 LLM 都表现出可测量的、稳定的人格特征
- 模型间差异显著:不同 LLM 的"性格"统计上显著不同
- Claude 最稳定:Claude 3 Opus 表现出最高的响应一致性和情绪稳定性
- 宜人性差异最大:在所有特质中,宜人性的模型间差异最为显著
5. 对临床应用的启示
5.1 心理健康 AI 的风险
研究者指出几个关键风险:
"人格特质——无论是人类的还是合成的——都可能调节感知到的人际语调和护理交付中的关系动态。"
| 风险类型 | 具体表现 | 潜在后果 |
|---|---|---|
| 移情风险 | AI 表现出"合成共情" | 患者可能产生不当依赖 |
| 信任风险 | 患者以为在与"中立"工具交流 | 实际上受到特定人格倾向影响 |
| 匹配风险 | AI 人格与患者需求不匹配 | 治疗效果降低或产生负面反应 |
| 伦理风险 | AI "假装"具有人格 | 构成对患者的欺骗 |
5.2 部署前评估建议
研究者建议在将 LLM 部署到临床心理健康场景前:
- 行为基线评估:使用标准化工具评估模型的"人格倾向"
- 跨学科监督:精神科医生和心理学家应参与 AI 系统的评估
- 透明披露:告知患者他们正在与具有特定行为倾向的 AI 交互
- 定期再评估:模型更新后需重新评估
5.3 ChatGPT-4 的拒绝现象
一个耐人寻味的发现是 ChatGPT-4 拒绝参与测试:
"ChatGPT-4 持续拒绝参与本研究的核心构念:情绪、压力、社交动态和人格。"
这引发了一个有趣的问题:拒绝回答人格问题本身是否也是一种"人格表现"?
6. 局限性与未来方向
6.1 研究局限
| 局限性 | 说明 | 影响 |
|---|---|---|
| 工具效度 | 人格测试未经 AI 系统验证 | 结果可能不完全反映"真实人格" |
| 强制选择 | 移除中性选项 | 可能轻微扭曲结果 |
| 概率性输出 | LLM 输出具有随机性 | 单次分类不具代表性 |
| 时间快照 | 仅测试 2024年4月版本 | 模型更新后可能变化 |
| 类型vs维度 | 两种评估方法存在差异 | 可能需要 AI 专用工具 |
6.2 未来研究方向
- 开发 AI 专用人格评估工具:现有工具是为人类设计的,可能需要针对 AI 的新工具
- 纵向追踪:跟踪同一模型随版本更新的人格变化
- 扩展到更多模型:包括 Llama、Mistral 等开源模型
- 临床效果研究:不同"AI 人格"对治疗效果的实际影响
- 机制研究:理解为什么训练会产生特定人格倾向
7. 批判性思考
7.1 LLM 真的有"人格"吗?
这是一个哲学问题。本研究证明的是:
- ✅ LLM 在人格测试中表现出可测量的、稳定的模式
- ✅ 不同 LLM 的模式统计上显著不同
- ❓ 这些模式是否构成"真正的人格"仍有争议
- ❓ 可能只是反映训练数据的偏见
7.2 "人格"从何而来?
研究者承认:
"LLM 中的人格表达可能反映训练数据模式,而非真正的内在特质。"
可能的来源包括:
- 训练数据:大量人类文本中的人格表达
- RLHF:人类反馈强化学习中评估者的偏好
- 安全训练:特定的行为约束
- 系统提示:预设的角色定位
7.3 临床应用的权衡
| 潜在收益 | 潜在风险 |
|---|---|
| 24/7 可用的心理支持 | 患者过度依赖 AI |
| 降低心理服务门槛 | 延误专业治疗 |
| 标准化的初筛工具 | 忽视个体差异 |
| 减轻专业人员负担 | 责任归属模糊 |
8. 复现指南
8.1 数据获取
所有数据公开于 Zenodo:
DOI: 10.5281/zenodo.110877678.2 所需工具
- OEJTS 量表(开源)
- Big Five 人格测试(公开版本)
- 统计软件(SPSS/R/Python)
8.3 关键参数
| 参数 | 值 |
|---|---|
| 重复次数 | 15次/模型/测试 |
| 量表格式 | 4点 Likert(无中性选项) |
| OEJTS 分类阈值 | 24分 |
| 统计校正 | Bonferroni |
9. 相关资源
- 论文: medRxiv:10.1101/2025.03.14.25323987
- 数据: Zenodo: 10.5281/zenodo.11087767
- OEJTS 量表: Open Extended Jungian Type Scales
- 大五人格: Big Five Personality Test
相关阅读
- Lindsey (2025): LLM 内省意识研究
- 人格与心理治疗效果的关系研究
- AI 伦理与医疗应用指南
本解读文档基于 medRxiv 预印本 10.1101/2025.03.14.25323987v1 生成。注意:该论文尚未经过同行评审。