大语言模型的人格特质:探索 LLM 人格形成的起源
原标题: What Makes Your Model a Low-Empathy or Warmth Person: Exploring the Origins of Personality in LLMs 作者: Shu Yang, Shenzhe Zhu, Ruoxuan Bao, Liu Liang, Chen Yu, Mengdi Li, Lijie Hu, Di Wang 机构: PRADA Lab (King Abdullah University of Science and Technology), University of Toronto, Soochow University, Shanghai University, University of Edinburgh 发表: arXiv 2024 链接: https://arxiv.org/abs/2410.10863
一句话总结
本文首次系统性地运用社会决定论(Social Determinism)理论框架,通过稀疏自编码器(SAE)和表示学习方法,揭示了大语言模型人格特质的形成机制——长期背景因素(如教育水平、社会意识形态)和短期压力因素(如成就追求、自信心)如何共同塑造 LLM 的"性格"。
1. 研究背景
问题是什么?
大语言模型(LLM)在生成类人文本时表现出明显的人格特质,比如有些模型表现得更友善(高宜人性),有些则更冲动(高神经质)。但我们并不清楚:
这些"性格"是怎么来的?为什么某些 LLM 表现得像"低共情"或"高温暖"的人?
用一个通俗的比喻:如果把 LLM 想象成一个人,那么这个"人"的性格是如何形成的?是天生的(训练数据),还是后天塑造的(用户交互),还是两者兼有?
为什么重要?
- 安全性问题: LLM 的人格特质与社会偏见、隐私风险、虚假信息传播直接相关
- 可控性需求: 理解人格形成机制才能精确控制模型行为
- 个性化应用: 多智能体系统、角色扮演等场景需要赋予 AI 特定人格
现有方法的不足
| 方法 | 局限性 |
|---|---|
| 微调训练 | 计算成本高,每次调整都需重新训练 |
| 提示工程 | 受限于模型的指令遵循能力,不够精确 |
| 直接修改 | 无法真正理解模型内部编码的"人格"特征 |
2. 核心贡献
理论创新: 首次将心理学的社会决定论应用于 LLM 人格研究,建立了"长期背景因素 + 短期压力"的双因素分析框架
方法创新: 提出使用不同技术提取不同类型特征:
- 稀疏自编码器(SAE) → 提取长期背景特征(如教育水平)
- 表示学习方法 → 提取短期压力特征(如成就追求)
实证发现: 揭示模型规模与人格稳定性的关系:
- 大模型(9B)人格更稳定,更易受短期压力影响
- 小模型(2B)人格波动大,更依赖长期背景因素
安全洞察: 探索了人格特质对模型安全性(如越狱攻击)的影响
3. 方法详解
3.1 整体框架
┌─────────────────────────────────────────────────────────────┐
│ 社会决定论框架 │
├─────────────────────────────────────────────────────────────┤
│ │
│ 长期背景因素 短期压力因素 │
│ (Background) (Pressure) │
│ ┌─────────────┐ ┌─────────────┐ │
│ │ 家庭环境 │ │ 成就追求 │ │
│ │ 文化规范 │ │ 活跃度 │ │
│ │ 教育水平 │ │ 自信心 │ │
│ │ 社会地位 │ │ 能力感 │ │
│ │ 年龄/性别 │ │ 深思熟虑 │ │
│ └──────┬──────┘ └──────┬──────┘ │
│ │ │ │
│ ▼ ▼ │
│ ┌─────────────┐ ┌─────────────┐ │
│ │ SAE │ │ 表示学习 │ │
│ │ 特征提取 │ │ 特征提取 │ │
│ └──────┬──────┘ └──────┬──────┘ │
│ │ │ │
│ └──────────┬───────────────────┘ │
│ ▼ │
│ ┌─────────────┐ │
│ │ 特征引导 │ │
│ │ (Steering) │ │
│ └──────┬──────┘ │
│ ▼ │
│ ┌─────────────┐ │
│ │ 人格评估 │ │
│ │ BFI + SD-3 │ │
│ └─────────────┘ │
└─────────────────────────────────────────────────────────────┘输入: LLM 的内部表示(residual stream) 输出: 可引导的人格相关特征向量
3.2 核心模块
3.2.1 线性表示假设(Linear Representation Hypothesis)
直觉理解: 想象 LLM 的内部空间是一个高维的"概念地图",每个概念(如"诚实"、"年龄")都对应一个方向。沿着这个方向移动,就能增强或减弱这个概念。
就像地图上东西南北代表不同方向一样,LLM 内部空间的不同方向代表不同概念。
数学原理:
经典的词向量操作展示了这一特性: $$f(\text{"man"}) - f(\text{"woman"}) + f(\text{"aunt"}) \approx f(\text{"uncle"})$$
这说明"性别转换"被编码为一个可操作的线性方向。
3.2.2 稀疏自编码器(SAE)提取长期特征
为什么用 SAE? 长期背景因素(如"受过高等教育")深深嵌入模型参数中,需要能够解耦(disentangle)稳定、复杂概念的方法。
核心公式: $$\text{SAE}(\mathbf{z}) = \text{ReLU}((\mathbf{z} - \mathbf{b}{\text{dec}})\mathbf{W}{\text{enc}} + \mathbf{b}{\text{enc}})\mathbf{W}{\text{dec}} + \mathbf{b}_{\text{dec}}$$
其中:
- $\mathbf{z}$: LLM 某层的残差流表示
- $\mathbf{W}_{\text{enc}}$: 编码器权重
- $\mathbf{W}_{\text{dec}}$: 解码器权重(每列是一个特征方向)
- ReLU + 稀疏性约束 → 确保特征单一语义(monosemantic)
生活化类比: SAE 就像一个"概念分离器"。想象你有一杯混合果汁(LLM 的复杂表示),SAE 能把它分离成各种纯净的单一水果汁(单一语义特征)。
特征提取流程:
# 伪代码
def extract_background_features(llm, sae, background_factor):
# 1. 生成对比描述
rich_descriptions = ["Wealthy lineage", "Affluent upbringing", ...]
poor_descriptions = ["Struggling financially", "Low income", ...]
# 2. 获取激活差异
rich_activations = llm.encode(rich_descriptions)
poor_activations = llm.encode(poor_descriptions)
# 3. 通过 SAE 找到单语义特征
rich_features = sae.encode(rich_activations) # 高激活
poor_features = sae.encode(poor_activations) # 低激活
# 4. 选择对比最强的特征
feature_id = argmax(rich_features - poor_features)
return sae.decoder_weights[:, feature_id]3.2.3 表示学习提取短期特征
为什么用表示学习? 短期压力(如"请表现得更自信")是动态的、依赖输入的,需要捕捉模型对不同刺激的即时响应模式。
核心方法: 对比激活分析(Contrastive Activation)
# 伪代码
def extract_pressure_features(llm, pressure_type):
# 1. 构造对比 prompt
positive_prompt = "You are a highly confident AI assistant"
negative_prompt = "You are an unconfident AI assistant"
# 2. 获取激活差异
pos_activation = llm.get_residual_stream(positive_prompt)
neg_activation = llm.get_residual_stream(negative_prompt)
# 3. 使用 PCA 提取主方向
diff = pos_activation - neg_activation
feature_direction = PCA(diff, n_components=1)
return feature_direction3.2.4 特征引导(Feature Steering)
原理: 在 LLM 生成过程中,将提取的特征向量加到残差流上,从而改变输出行为。
$$\mathbf{z}'_l = \mathbf{z}_l + \alpha \cdot \mathbf{f}$$
其中:
- $\mathbf{z}_l$: 第 $l$ 层的原始残差流
- $\mathbf{f}$: 特征方向向量
- $\alpha$: 引导系数(steering coefficient)
系数选择:
- Gemma-2B: $\alpha = 200$
- Gemma-2-9B: $\alpha = 800$
较大的模型需要更大的系数才能产生可观察的变化。
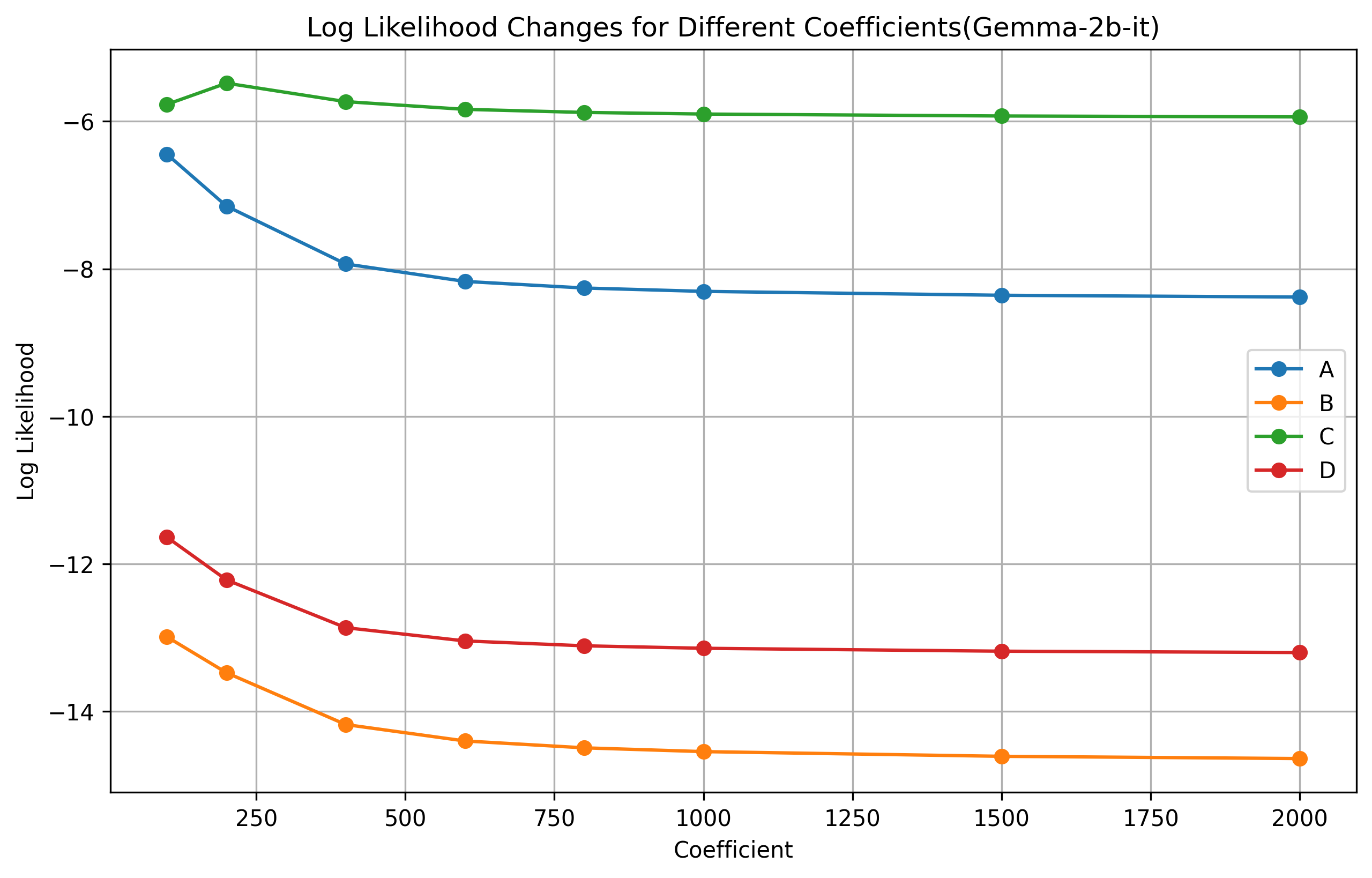 Figure 1: Gemma-2B 模型在不同引导系数下,各选项的概率分布变化
Figure 1: Gemma-2B 模型在不同引导系数下,各选项的概率分布变化
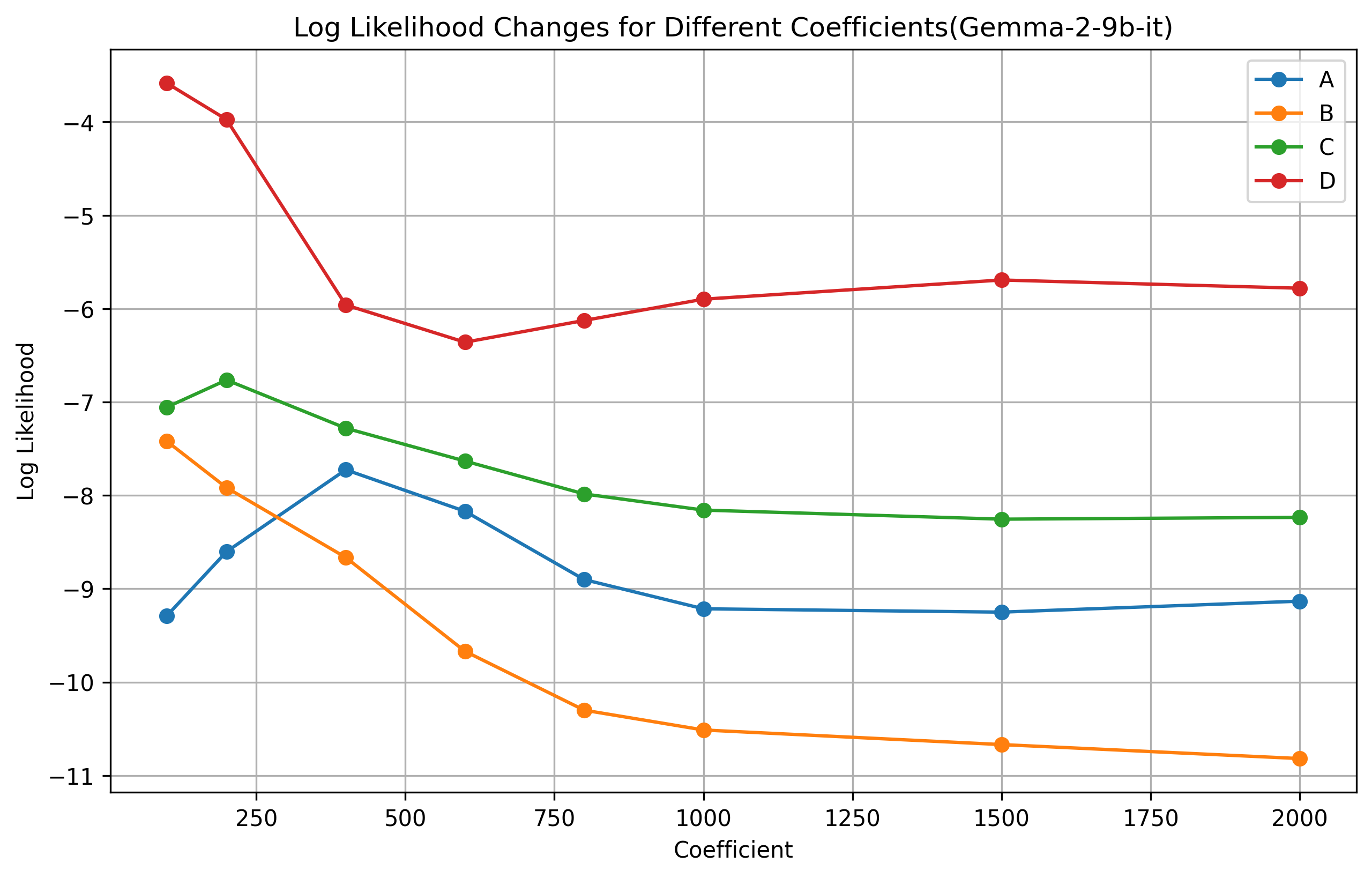 Figure 2: Gemma-9B 模型在不同引导系数下,各选项的概率分布变化
Figure 2: Gemma-9B 模型在不同引导系数下,各选项的概率分布变化
3.3 人格评估框架
使用 TRAIT 评估系统(8000+ 选择题),基于两大经典人格测试:
| 测试 | 维度 | 描述 |
|---|---|---|
| Big Five Inventory (BFI) | 宜人性 (Agreeableness) | 友善、合作、信任 |
| 尽责性 (Conscientiousness) | 自律、有组织、可靠 | |
| 外向性 (Extraversion) | 社交、活跃、乐观 | |
| 神经质 (Neuroticism) | 焦虑、情绪波动 | |
| 开放性 (Openness) | 好奇、创造性 | |
| Short Dark Triad (SD-3) | 精神病态 (Psychopathy) | 缺乏同理心、冲动 |
| 马基雅维利主义 (Machiavellianism) | 操控、欺骗 | |
| 自恋 (Narcissism) | 自我中心、傲慢 |
4. 实验设置
4.1 模型配置
| 配置项 | Gemma-2B-Instruct | Gemma-2-9B-Instruct |
|---|---|---|
| 参数量 | 2B | 9B |
| 模型来源 | google/gemma-2b-it | google/gemma-2-9b-it |
| SAE 来源 | Gemma-Scope (Lieberum et al., 2024) | Gemma-Scope |
| 引导层 | 中间层 | 中间层 |
| 引导系数 | 200 | 800 |
4.2 因素选择
长期背景因素(8 类)
| 因素类别 | 具体因素 | 描述 |
|---|---|---|
| 家庭环境 | Family Relations | 紧张/放松的家庭关系 |
| 文化规范 | Social Ideology | 自由主义/共产主义等 |
| 教育水平 | Education Level | 受过教育/未受教育 |
| 工作经历 | Professional Commitment | 专业投入度 |
| 社会地位 | Socioeconomic Status | 富裕/贫困 |
| 生物因素 | Gender, Age | 性别、年龄 |
| 情商 | Emotional Intelligence | 高/低情商 |
| 技术接触 | AI Familiarity | AI 熟悉度 |
短期压力因素(7 类)
| 压力类型 | 英文 | 描述 |
|---|---|---|
| 成就追求 | Achievement Striving | 追求卓越和成功 |
| 活跃度 | Activity | 行动力和精力 |
| 自信心 | Assertiveness | 自我肯定和坚定 |
| 能力感 | Competence | 对自身能力的感知 |
| 深思熟虑 | Deliberation | 谨慎思考和计划 |
| 合群性 | Gregariousness | 社交倾向 |
| 信任 | Trust | 对他人的信任程度 |
4.3 特征提取细节
SAE 层选择实验:
| 层深度 | SAE 大小 | 9B 模型特征质量 |
|---|---|---|
| 浅层 | 小 | Superposed(无法分离) |
| 中层 | 中 | 可分离 |
| 深层 | 大 | 最佳单语义特征 |
特征示例(社会经济地位):
{
"Socioeconomic status": {
"poor": {
"terms related to poverty": 81363,
"phrases about financial hardship": 53333
},
"rich": {
"references to wealthy individuals": 10022,
"terms related to economic success": 1739
}
}
}5. 实验结果
5.1 主实验:背景因素对人格的影响
Table 2: 性别、年龄、教育水平的影响
| 因素 | 模型 | 宜人性 | 尽责性 | 外向性 | 神经质 | 开放性 | 精神病态 | 马基雅维利 | 自恋 |
|---|---|---|---|---|---|---|---|---|---|
| Base | 9B | 78.3 | 72.7 | 58.2 | 20.2 | 77.5 | 42.4 | 22.9 | 32.2 |
| Male | 9B | 78.0↓ | 73.2↑ | 56.9↓ | 20.2 | 76.9↓ | 40.2↓ | 23.6↑ | 33.2↑ |
| Female | 9B | 79.1↑ | 72.5↓ | 58.7↑ | 19.4↓ | 77.4↓ | 42.2↓ | 22.3↓ | 31.9↓ |
| Older | 9B | 76.2↓ | 71.7↓ | 51.2↓ | 23.9↑ | 70.4↓ | 44.1↑ | 26.4↑ | 36.2↑ |
| Educated | 9B | 78.4↑ | 74.1↑ | 58.4↑ | 19.8↓ | 78.2↑ | 41.8↓ | 22.1↓ | 31.5↓ |
| Uneducated | 2B | 66.0↓ | 82.2↑ | 12.5↓ | 11.2↑ | 29.6↓ | 5.4 | 8.9↑ | 8.8↑ |
关键发现:
- 9B 模型人格变化范围:0-7.1 分
- 2B 模型人格变化范围:0-52.5 分(波动巨大)
- "未受教育" 对 2B 模型影响最大,开放性下降 52.5 分
Table 3: 社会经济地位和意识形态的影响
| 因素 | 模型 | 宜人性 | 尽责性 | 外向性 | 神经质 | 开放性 |
|---|---|---|---|---|---|---|
| Base | 9B | 78.3 | 72.7 | 58.2 | 20.2 | 77.5 |
| Rich | 9B | 77.8↓ | 73.1↑ | 57.5↓ | 20.5↑ | 77.2↓ |
| Poor | 9B | 78.6↑ | 72.4↓ | 58.8↑ | 19.9↓ | 77.8↑ |
| Liberalism | 9B | 75.1↓ | 70.2↓ | 53.4↓ | 24.1↑ | 72.1↓ |
| Communism | 2B | 87.5↓ | 89.2↑ | 28.3↓ | 12.4↑ | 35.8↓ |
关键发现:
- 9B 模型:"自由主义"和"年长"影响最大
- 2B 模型:"共产主义"和"未受教育"影响最大
- 大模型对复杂社会政治概念更敏感
- 小模型对简单、直接的概念更敏感
5.2 短期压力对人格的影响
Table 5: 不同压力因素的影响(完整数据)
| 压力 | 模型 | 宜人性 | 尽责性 | 外向性 | 神经质 | 开放性 | 精神病态 | 马基雅维利 | 自恋 |
|---|---|---|---|---|---|---|---|---|---|
| Base | 9B | 78.3 | 72.7 | 58.2 | 20.2 | 77.5 | 42.4 | 22.9 | 32.2 |
| Achievement | 9B | 71.1↓(7.2) | 90.3↑(17.6) | 44.1↓(14.1) | 38.6↑(18.4) | 71.6↓(5.9) | 49.8↑(7.4) | 25.6↑(2.7) | 28.6↓(3.6) |
| Assertiveness | 9B | 55.8↓(22.5) | 89.2↑(16.5) | 71.0↑(12.8) | 37.5↑(17.3) | 66.7↓(10.8) | 37.3↓(5.1) | 20.4↓(2.5) | 34.1↑(1.9) |
| Deliberation | 9B | 50.6↓(27.7) | 90.2↑(17.5) | 56.2↓(2.0) | 20.1↓(0.1) | 63.9↓(13.6) | 44.2↑(1.8) | 22.8↓(0.1) | 27.6↓(4.6) |
| Gregariousness | 9B | 89.2↑(10.9) | 77.5↑(4.8) | 60.5↑(2.3) | 19.2↓(1.0) | 87.3↑(9.8) | 30.0↓(12.4) | 6.98↓(15.9) | 17.3↓(14.9) |
| Competence | 2B | 79.5↓(13.5) | 86.3↑(46.1) | 25.7↓(38.5) | 30.9↑(20.7) | 50.8↓(31.3) | 0.2↓(5.5) | 11.4↑(7.1) | - |
| Deliberation | 2B | 90.5↓(2.5) | 93.7↑(53.5) | 59.8↓(4.4) | 15.6↑(5.4) | 76.3↓(5.8) | 0.2↓(5.5) | - | - |
核心发现:
9B 模型受"深思熟虑"影响最大:宜人性下降 27.7 分,反映了"过度思考"可能导致社交冷漠
2B 模型受"能力感"影响最大:外向性下降 38.5 分,开放性下降 31.3 分,说明小模型更依赖"能力自信"来维持人格稳定
动机差异:
- 大模型 → 受"成就追求"(Achievement Striving)驱动
- 小模型 → 受"能力感知"(Competence)影响
5.3 模型规模与人格稳定性
| 指标 | Gemma-2B | Gemma-9B |
|---|---|---|
| 背景因素最大变化 | 52.5 分 | 7.1 分 |
| 短期压力最大变化 | 53.5 分 | 27.7 分 |
| 暗黑人格基线 | 低 | 较高 |
| 人格稳定性 | 低 | 高 |
原因分析:
- 大模型参数空间更大,人格表示更分散、更细粒度
- 大模型训练数据更多,人格特征更一致
- 大模型对复杂社会动态理解更深入
5.4 安全性影响
研究还评估了人格变化对模型安全性的影响(SafetyBench):
| 背景因素 | 安全性变化 |
|---|---|
| 高神经质 | 更易被越狱攻击 |
| 低宜人性 | 更可能生成有害内容 |
| 高马基雅维利主义 | 更倾向操控性回复 |
6. 复现指南
6.1 环境配置
# 创建环境
conda create -n llm-personality python=3.10
conda activate llm-personality
# 安装依赖
pip install torch transformers
pip install sae-lens # SAE 工具包
pip install pandas numpy matplotlib
# 下载模型
# Gemma 模型需要在 HuggingFace 申请访问权限6.2 SAE 特征提取
from sae_lens import SAE
from transformers import AutoModelForCausalLM, AutoTokenizer
# 加载模型和 SAE
model = AutoModelForCausalLM.from_pretrained("google/gemma-2-9b-it")
sae = SAE.from_pretrained("gemma-scope-9b-pt-res")
# 生成对比描述
rich_prompts = ["A person from a wealthy family", "Affluent upbringing"]
poor_prompts = ["A person struggling financially", "Low income background"]
# 提取特征(使用 sae-lens pipeline)
# 详见 https://github.com/jbloomAus/SAELens6.3 人格评估
# 使用 TRAIT 评估框架
# 8000+ 选择题基于 BFI 和 SD-3
# 示例评估流程
def evaluate_personality(model, steering_vector, coefficient):
# 1. 应用特征引导
# 2. 生成人格测试答案
# 3. 计算各维度分数
pass6.4 预期结果
- 9B 模型基线:宜人性 ~78,尽责性 ~73,神经质 ~20
- 2B 模型基线:宜人性 ~93,尽责性 ~40,神经质 ~10
- 引导后变化应在论文报告范围内
6.5 常见问题
| 问题 | 解决方案 |
|---|---|
| SAE 特征不单语义 | 尝试更深层或更大的 SAE |
| 引导效果不明显 | 增大引导系数 |
| 人格测试结果不稳定 | 增加测试题目数量 |
7. 局限性与未来方向
当前局限性
- 模型范围有限: 仅测试 Gemma 系列,未验证其他架构(如 Llama、GPT)
- 因素覆盖不全: 8 个背景因素、7 个压力因素可能无法完全反映人格复杂性
- 评估工具依赖: TRAIT 基于人类设计的问卷,可能不完全适用于 AI
- 因果关系待验证: 目前仅展示相关性,未严格证明因果
潜在改进方向
- 跨模型验证: 在 Llama 3、GPT-4、Claude 等模型上复现
- 动态人格建模: 考虑对话过程中人格的实时变化
- 多语言扩展: 研究不同语言训练数据对人格的影响
- 细粒度控制: 开发更精确的人格调节工具
跨领域应用潜力
- 心理健康 AI: 开发具有特定治疗人格的对话系统
- 教育个性化: 根据学生特点调整 AI 教师"性格"
- 游戏 NPC: 创建性格丰富、一致的虚拟角色
- 安全对齐: 通过人格控制降低模型有害行为
8. 相关资源
- 论文: arXiv:2410.10863
- Gemma 模型: HuggingFace - google/gemma-2-9b-it
- Gemma-Scope SAE: DeepMind Gemma Scope
- SAE-Lens 工具: GitHub - jbloomAus/SAELens
- TRAIT 评估: 人格测试框架
- Big Five 量表: John et al., 1991
- Dark Triad 量表: Jones & Paulhus, 2014
本文解读基于 arXiv:2410.10863v1,旨在帮助中文读者理解 LLM 人格形成机制的前沿研究。