多智能体工作流简单案例
本章通过一个实际案例,展示如何使用 LangGraph 构建多智能体工作流系统。
案例概述
本案例实现了一个 多智能体协作系统,采用 Supervisor 模式 来协调多个 Agent 完成不同类型的任务。
系统架构
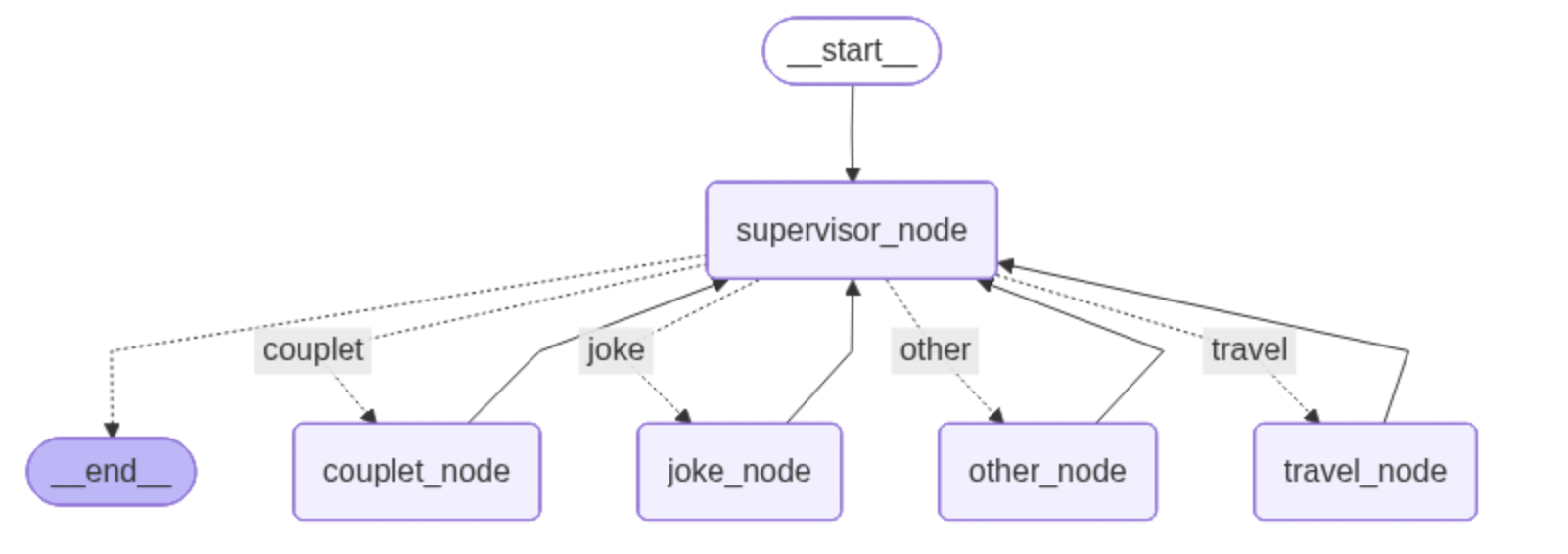
角色说明
本系统包含以下核心角色:
| 角色 | 功能 | 技术实现 |
|---|---|---|
| Client | 用户接口 | 接收用户输入并返回结果 |
| Supervisor | 调度中心 | 分析用户意图并分配给合适的 Agent |
| 路线规划 Agent | 规划路线 | LLM + MCP 工具 |
| 对联生成 Agent | 生成对联 | LLM + RAG 知识库 |
| 笑话 Agent | 讲笑话 | 纯 LLM 生成 |
| 拒绝 Agent | 兜底处理 | 处理无法识别的请求 |
工作流程
本系统的多智能体工作流遵循以下步骤:
- 接收请求:用户 Agent 接收用户输入并传递给系统
- 意图分析:Supervisor 分析请求内容,判断属于哪类任务
- 任务分发:Agent 调用相应工具(RAG/MCP)执行任务
- 结果汇总:各 Agent 将结果返回给 Supervisor 整合
关键术语解释
在开始代码实现之前,让我们先了解一些 LangGraph 中的关键概念:
State(状态)
State 是 LangGraph 中贯穿整个工作流的数据容器。可以把它想象成一个「共享的笔记本」,所有节点都可以读取和写入这个笔记本。每个节点执行完毕后,都会更新 State,下一个节点就能看到最新的数据。
class State(TypedDict):
messages: Annotated[list[BaseMessage], add_messages] # 消息列表
type: str # 当前分类类型Annotated 和 add_messages
Annotated 是 Python 类型提示的一个特性,用于给类型添加额外信息。在 LangGraph 中,它配合 reducer 函数(如 add_messages 或 add)来决定状态如何更新:
add_messages:专门用于消息列表,会智能合并新旧消息add:简单的列表拼接,把新元素追加到列表末尾
简单来说,当你返回新的 messages 时,系统不会覆盖旧消息,而是把新消息追加进去。
StateGraph(状态图)
StateGraph 是构建工作流的核心类。你可以把它想象成一块「白板」,在上面画出各个节点(Agent)以及它们之间的连线(边)。
节点(Node)
节点就是执行具体任务的函数。每个节点接收当前 State,执行一些操作,然后返回更新后的数据。
条件边(Conditional Edges)
条件边允许你根据某些条件来决定下一步走哪个节点。就像一个「交通指挥」,根据当前情况指引流量走向不同方向。
get_stream_writer
get_stream_writer 是 LangGraph 提供的流式输出工具,允许节点在执行过程中实时输出信息,而不是等到整个工作流结束才返回结果。
InMemorySaver / Checkpointer
Checkpointer 是用来保存工作流状态的组件。InMemorySaver 是其中一种实现,把状态保存在内存中。这让你可以:
- 暂停和恢复工作流
- 查看历史状态
- 实现会话的持久化
代码实现
第一步:连接 LLM
首先,我们需要连接到 OpenAI 的语言模型:
from langchain_openai import ChatOpenAI
import getpass
llm = ChatOpenAI(
model="gpt-4o-mini",
api_key=getpass.getpass("OpenAI Key: "),
)
print(llm.invoke("Hi").content)运行结果:
Hello! How can I assist you today?第二步:定义完整的多智能体系统
下面是完整的 Supervisor + 多 Agent 系统实现:
from typing import TypedDict, Annotated
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage, AIMessage, BaseMessage
from langgraph.checkpoint.memory import InMemorySaver
from langgraph.config import get_stream_writer
from langgraph.constants import START, END
from langgraph.graph.message import add_messages
from operator import add
from langgraph.graph import StateGraph
llm = ChatOpenAI(model="gpt-4o-mini")
# -----------------------------------------------------
# 0. 工具函数(核心:自动抽取 msg 内容 + 标准化)
# -----------------------------------------------------
def extract_content(msg):
"""
抽取 message 内容并统一格式为 string。
支持:
- str
- HumanMessage / AIMessage
- dict ({"type": ..., "content": ...})
"""
if isinstance(msg, BaseMessage):
return msg.content
if isinstance(msg, dict) and "content" in msg:
return msg["content"]
return str(msg)
def ensure_human_message(msg):
"""
将任何类型消息安全转换为 HumanMessage。
为了保持 messages 格式一致,避免混入 str/dict。
"""
content = extract_content(msg)
return HumanMessage(content=content)
# -----------------------------------------------------
# 1. 定义状态
# -----------------------------------------------------
class State(TypedDict):
messages: Annotated[list[BaseMessage], add_messages] # 强制 messages 统一为 BaseMessage
type: str
# -----------------------------------------------------
# 2. 各个节点
# -----------------------------------------------------
def supervisor_node(state: State):
writer = get_stream_writer()
writer({"node": "supervisor_node"})
# 如果已经分好类
if state.get("type") and state["type"] != "":
return {"type": "__end__"}
# 获取用户输入
user_msg = extract_content(state["messages"][0])
# 分类 prompt
system_prompt = """
你是一个专业的客服助手,请将用户的问题分类为以下几类之一:
travel / joke / couplet / other
不要返回其他内容。
"""
response = llm.invoke([
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_msg},
])
type_result = extract_content(response)
writer({"supervisor_result": type_result})
return {"type": type_result}
def joke_node(state: State):
writer = get_stream_writer()
writer({"node": "joke_node"})
user_msg = extract_content(state["messages"][0])
system_prompt = "你是一个笑话大师,根据用户的问题,写一个不超过100个字的笑话。"
response = llm.invoke([
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_msg},
])
joke_result = extract_content(response)
writer({"joke_result": joke_result})
return {
"messages": [HumanMessage(content=joke_result)],
"type": "joke"
}
def travel_node(state: State):
writer = get_stream_writer()
writer({"node": "travel_node"})
return {
"messages": [HumanMessage(content="我推荐你去北京")],
"type": "travel"
}
def couplet_node(state: State):
writer = get_stream_writer()
writer({"node": "couplet_node"})
return {
"messages": [HumanMessage(content="上联:春风得意马蹄疾")],
"type": "couplet"
}
def other_node(state: State):
writer = get_stream_writer()
writer({"node": "other_node"})
return {
"messages": [HumanMessage(content="暂时无法回答你的问题")],
"type": "other"
}
# -----------------------------------------------------
# 3. routing function
# -----------------------------------------------------
def routing_func(state: State):
t = state["type"]
if t in ("travel", "joke", "couplet", "other"):
return t
elif t == "__end__":
return "__end__"
else:
return "other"
# -----------------------------------------------------
# 4. 构建 Graph
# -----------------------------------------------------
builder = StateGraph(State)
# 添加节点
builder.add_node("supervisor_node", supervisor_node)
builder.add_node("joke_node", joke_node)
builder.add_node("travel_node", travel_node)
builder.add_node("couplet_node", couplet_node)
builder.add_node("other_node", other_node)
# start → supervisor
builder.add_edge(START, "supervisor_node")
# supervisor → conditional routing
builder.add_conditional_edges(
"supervisor_node",
routing_func,
{
"joke": "joke_node",
"travel": "travel_node",
"couplet": "couplet_node",
"other": "other_node",
"__end__": END,
}
)
# workers → supervisor(循环)
builder.add_edge("joke_node", "supervisor_node")
builder.add_edge("travel_node", "supervisor_node")
builder.add_edge("couplet_node", "supervisor_node")
builder.add_edge("other_node", "supervisor_node")
# -----------------------------------------------------
# 5. 编译图
# -----------------------------------------------------
checkpointer = InMemorySaver()
graph = builder.compile(checkpointer=checkpointer)
graph
from IPython.display import Image, display
display(Image(react_graph.get_graph(xray=True).draw_mermaid_png()))Graph 可视化
编译完成后,LangGraph 会生成如下的工作流图:
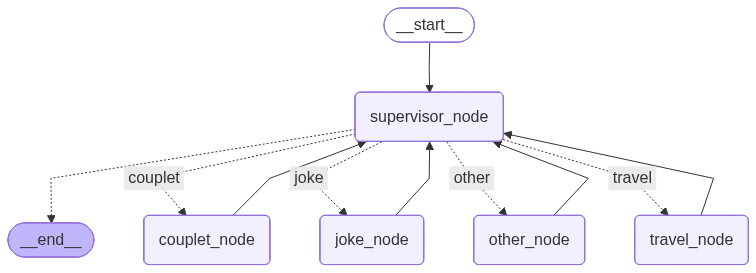
从图中可以看到:
- START 节点作为入口,首先进入 supervisor_node
- supervisor_node 根据用户输入的分类结果,通过条件边路由到对应的 worker 节点
- 每个 worker 节点(joke_node、travel_node、couplet_node、other_node)执行完任务后,都会返回 supervisor_node
- 当 supervisor 检测到任务已完成(type 已设置),就路由到 END 结束工作流
运行示例
stream_mode="values" 模式
这种模式会输出每个步骤后的完整状态值:
config = {"configurable": {"thread_id": "2"}}
for chunk in graph.stream(
{"messages": ["讲个5个字以内的笑话,请你严格控制字数!"]},
config,
stream_mode="values"
):
print(chunk)运行结果:
{'messages': [HumanMessage(content='讲个5个字以内的笑话,请你严格控制字数!', ...)]}
{'messages': [HumanMessage(content='讲个5个字以内的笑话,请你严格控制字数!', ...)], 'type': 'joke'}
{'messages': [HumanMessage(content='讲个5个字以内的笑话,请你严格控制字数!', ...), HumanMessage(content='鱼在水里!', ...)], 'type': 'joke'}
{'messages': [HumanMessage(content='讲个5个字以内的笑话,请你严格控制字数!', ...), HumanMessage(content='鱼在水里!', ...)], 'type': '__end__'}从输出可以看到工作流的执行过程:
- 用户消息进入系统
- Supervisor 分类为 "joke"
- joke_node 生成笑话 "鱼在水里!"
- 返回 supervisor,检测到 type 已设置,结束流程
stream_mode="debug" 模式
这种模式会输出详细的调试信息,包括每个步骤的 checkpoint、task 信息等:
config = {"configurable": {"thread_id": "3"}}
for chunk in graph.stream(
{"messages": ["讲个5个字以内的笑话,请你严格控制字数!"]},
config,
stream_mode="debug"
):
print(chunk)运行结果(部分):
{'step': 0, 'timestamp': '2025-12-01T11:18:17.892007+00:00', 'type': 'checkpoint', ...}
{'step': 1, 'type': 'task', 'payload': {'name': 'supervisor_node', ...}}
{'step': 1, 'type': 'task_result', 'payload': {'name': 'supervisor_node', 'result': {'type': 'joke'}, ...}}
{'step': 2, 'type': 'task', 'payload': {'name': 'joke_node', ...}}
{'step': 2, 'type': 'task_result', 'payload': {'name': 'joke_node', 'result': {'messages': [HumanMessage(content='猪说:"我胖!"', ...)], 'type': 'joke'}, ...}}
{'step': 3, 'type': 'task', 'payload': {'name': 'supervisor_node', ...}}
{'step': 3, 'type': 'task_result', 'payload': {'name': 'supervisor_node', 'result': {'type': '__end__'}, ...}}debug 模式非常适合排查工作流问题,可以看到:
- 每个步骤的编号(step)
- 每个任务的名称和触发器
- 每个任务的执行结果
- checkpoint 的状态变化
stream_mode="custom" 模式
这种模式只输出通过 get_stream_writer() 主动写入的自定义信息:
config = {"configurable": {"thread_id": "4"}}
for chunk in graph.stream(
{"messages": ["讲个5个字以内的笑话,请你严格控制字数!"]},
config,
stream_mode="custom"
):
print(chunk)运行结果:
{'node': 'supervisor_node'}
{'supervisor_result': 'joke'}
{'node': 'joke_node'}
{'joke_result': '鱼说:"水来了!"'}
{'node': 'supervisor_node'}custom 模式非常简洁,只显示我们在代码中通过 writer() 主动输出的信息,适合生产环境中向用户展示关键进度。
各 Agent 详解
1. Supervisor 调度中心
Supervisor 是整个系统的"大脑",负责任务分发:
- 接收用户请求并分析意图
- 根据意图类型选择合适的 Agent
- 将任务分配给对应的 Agent
- 收集 Agent 结果并返回给用户
核心逻辑:
def supervisor_node(state: State):
# 如果已经分好类,直接结束
if state.get("type") and state["type"] != "":
return {"type": "__end__"}
# 使用 LLM 分析用户意图
system_prompt = """
你是一个专业的客服助手,请将用户的问题分类为以下几类之一:
travel / joke / couplet / other
不要返回其他内容。
"""
response = llm.invoke([...])
return {"type": response.content}2. 路线规划 Agent
本 Agent 负责使用 LangGraph 内置的 MCP 工具 进行路线规划:
- 接收用户的路线规划请求
- 调用高德地图等 MCP 工具获取路线信息
- 整理并返回规划结果
核心技术:MCP 工具集成
3. 对联生成 Agent
本 Agent 使用 RAG 知识库 来生成对联:
- 分析用户给出的上联
- 通过向量检索找到相关的对联知识
- 结合检索结果让 LLM 生成合适的下联
核心技术:向量检索 + RAG 增强生成
4. 笑话 Agent
最简单的 Agent,纯 LLM 调用:
def joke_node(state: State):
user_msg = extract_content(state["messages"][0])
system_prompt = "你是一个笑话大师,根据用户的问题,写一个不超过100个字的笑话。"
response = llm.invoke([
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_msg},
])
return {
"messages": [HumanMessage(content=response.content)],
"type": "joke"
}核心技术:纯 LLM 生成,无工具调用
5. 拒绝 Agent
兜底 Agent,处理无法识别的请求:
- 当请求不属于任何已知类别时激活
- 礼貌地告知用户暂不支持该功能
学习目标
通过本案例你将学习:
| 技术点 | 说明 |
|---|---|
| Graph 构建 | 使用 StateGraph 构建多智能体系统 |
| 条件路由 | 使用条件边实现 LLM 智能路由 |
| MCP 集成 | 使用 Agent 内置 MCP 工具 |
| RAG 应用 | 使用向量检索增强生成 |
| 状态管理 | 使用多 Agent 共享状态管理 |
为什么学习本案例?
本案例虽然只是一个 Demo,但完整展示了多智能体系统的核心设计模式!
使用 LangChain 生态时,LangChain 适合简单的链式调用,而需要复杂的状态管理、分支逻辑时,LangGraph 才是正确的选择。学会用简单案例掌握多智能体系统的设计模式,未来就能应对更复杂的业务场景。
本案例将帮助你理解 LangGraph 实现多智能体协作的核心概念:状态流转、条件路由、工具集成等关键技术。
完整代码
下面是本案例的完整代码,可以直接复制运行:
from typing import TypedDict, Annotated
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage, AIMessage, BaseMessage
from langgraph.checkpoint.memory import InMemorySaver
from langgraph.config import get_stream_writer
from langgraph.constants import START, END
from langgraph.graph.message import add_messages
from operator import add
from langgraph.graph import StateGraph
# 初始化 LLM
llm = ChatOpenAI(model="gpt-4o-mini")
# -----------------------------------------------------
# 工具函数
# -----------------------------------------------------
def extract_content(msg):
"""
抽取 message 内容并统一格式为 string。
支持: str, HumanMessage/AIMessage, dict
"""
if isinstance(msg, BaseMessage):
return msg.content
if isinstance(msg, dict) and "content" in msg:
return msg["content"]
return str(msg)
def ensure_human_message(msg):
"""将任何类型消息安全转换为 HumanMessage。"""
content = extract_content(msg)
return HumanMessage(content=content)
# -----------------------------------------------------
# 定义状态
# -----------------------------------------------------
class State(TypedDict):
messages: Annotated[list[BaseMessage], add_messages]
type: str
# -----------------------------------------------------
# 节点定义
# -----------------------------------------------------
def supervisor_node(state: State):
"""Supervisor 节点:分析用户意图并路由到对应 Agent"""
writer = get_stream_writer()
writer({"node": "supervisor_node"})
# 如果已经分好类,结束流程
if state.get("type") and state["type"] != "":
return {"type": "__end__"}
# 获取用户输入
user_msg = extract_content(state["messages"][0])
# 分类 prompt
system_prompt = """
你是一个专业的客服助手,请将用户的问题分类为以下几类之一:
travel / joke / couplet / other
不要返回其他内容。
"""
response = llm.invoke([
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_msg},
])
type_result = extract_content(response)
writer({"supervisor_result": type_result})
return {"type": type_result}
def joke_node(state: State):
"""笑话 Agent:根据用户请求生成笑话"""
writer = get_stream_writer()
writer({"node": "joke_node"})
user_msg = extract_content(state["messages"][0])
system_prompt = "你是一个笑话大师,根据用户的问题,写一个不超过100个字的笑话。"
response = llm.invoke([
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_msg},
])
joke_result = extract_content(response)
writer({"joke_result": joke_result})
return {
"messages": [HumanMessage(content=joke_result)],
"type": "joke"
}
def travel_node(state: State):
"""旅行 Agent:提供旅行建议"""
writer = get_stream_writer()
writer({"node": "travel_node"})
return {
"messages": [HumanMessage(content="我推荐你去北京")],
"type": "travel"
}
def couplet_node(state: State):
"""对联 Agent:生成对联"""
writer = get_stream_writer()
writer({"node": "couplet_node"})
return {
"messages": [HumanMessage(content="上联:春风得意马蹄疾")],
"type": "couplet"
}
def other_node(state: State):
"""兜底 Agent:处理无法识别的请求"""
writer = get_stream_writer()
writer({"node": "other_node"})
return {
"messages": [HumanMessage(content="暂时无法回答你的问题")],
"type": "other"
}
# -----------------------------------------------------
# 路由函数
# -----------------------------------------------------
def routing_func(state: State):
"""根据分类结果决定下一个节点"""
t = state["type"]
if t in ("travel", "joke", "couplet", "other"):
return t
elif t == "__end__":
return "__end__"
else:
return "other"
# -----------------------------------------------------
# 构建 Graph
# -----------------------------------------------------
builder = StateGraph(State)
# 添加节点
builder.add_node("supervisor_node", supervisor_node)
builder.add_node("joke_node", joke_node)
builder.add_node("travel_node", travel_node)
builder.add_node("couplet_node", couplet_node)
builder.add_node("other_node", other_node)
# 添加边:START → supervisor
builder.add_edge(START, "supervisor_node")
# 添加条件边:supervisor → 各 worker 或 END
builder.add_conditional_edges(
"supervisor_node",
routing_func,
{
"joke": "joke_node",
"travel": "travel_node",
"couplet": "couplet_node",
"other": "other_node",
"__end__": END,
}
)
# 添加边:各 worker → supervisor(形成循环)
builder.add_edge("joke_node", "supervisor_node")
builder.add_edge("travel_node", "supervisor_node")
builder.add_edge("couplet_node", "supervisor_node")
builder.add_edge("other_node", "supervisor_node")
# -----------------------------------------------------
# 编译并运行
# -----------------------------------------------------
checkpointer = InMemorySaver()
graph = builder.compile(checkpointer=checkpointer)
# 运行示例
if __name__ == "__main__":
config = {"configurable": {"thread_id": "1"}}
for chunk in graph.stream(
{"messages": ["讲个5个字以内的笑话"]},
config,
stream_mode="custom"
):
print(chunk)参考来源:https://www.bilibili.com/video/BV1T2k6BaEEz/
下一步
接下来我们将在此基础上扩展更复杂的功能:
- 为路线规划 Agent 集成 MCP 工具
- 为对联 Agent 添加 RAG 知识库
- 实现更复杂的多轮对话状态管理
- 添加错误处理和重试机制
让我们继续探索 LangGraph 的更多可能性!