Agentic 工作流模式
五种核心工作流模式:从简单串联到复杂协作
概述
Agentic 工作流模式定义了智能体如何组织和执行任务。选择合适的工作流模式,是构建高效 Agentic RAG 系统的关键。
| 工作流模式 | 核心特征 | 延迟影响 | 适用场景 |
|---|---|---|---|
| 提示链(Prompt Chaining) | 顺序执行 | 较高 | 多步骤累积任务 |
| 路由(Routing) | 分类导向 | 中性 | 多类型查询处理 |
| 并行化(Parallelization) | 同时执行 | 降低 | 独立子任务 |
| 编排-工作者(Orchestrator-Workers) | 动态分配 | 可变 | 复杂动态任务 |
| 评估-优化(Evaluator-Optimizer) | 迭代改进 | 较高 | 质量敏感任务 |
一、提示链模式(Prompt Chaining)
提示链将复杂任务分解为顺序执行的步骤,每一步的输出作为下一步的输入。
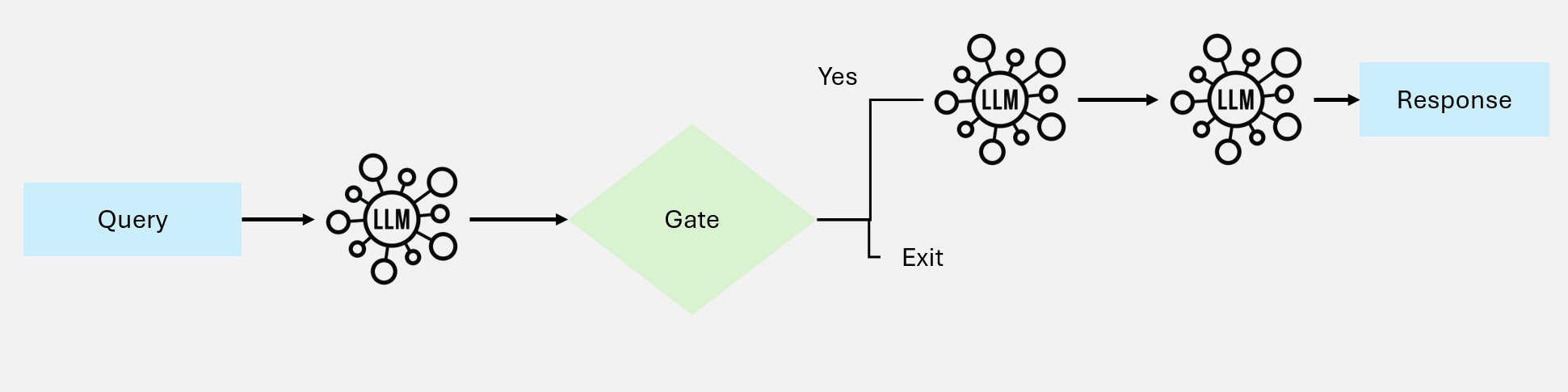 图 1:提示链工作流
图 1:提示链工作流
工作原理
输入 → 步骤1 → 输出1 → 步骤2 → 输出2 → 步骤3 → 最终输出
↓ ↓ ↓
简化子任务 累积结果 精确控制核心特点
- 顺序依赖:后一步依赖前一步的输出
- 逐步简化:将复杂问题分解为简单子问题
- 累积构建:最终结果由各步骤成果累积而成
典型应用
1. 多语言营销内容生成
步骤1:生成英文营销文案
↓
步骤2:翻译为中文(保留品牌调性)
↓
步骤3:翻译为日文(适应文化习惯)
↓
步骤4:翻译为西班牙文
↓
最终输出:四语言营销套件2. 研究报告撰写
步骤1:生成报告大纲
↓
步骤2:验证大纲完整性和逻辑性
↓
步骤3:扩展各章节内容
↓
步骤4:添加引用和数据
↓
步骤5:格式化和润色实现示例
python
def prompt_chaining(query):
# 步骤1:分析查询意图
intent = llm.analyze_intent(query)
# 步骤2:基于意图检索
docs = retriever.retrieve(query, intent=intent)
# 步骤3:提取关键信息
key_info = llm.extract_key_points(docs)
# 步骤4:生成初稿
draft = llm.generate_draft(query, key_info)
# 步骤5:润色优化
final = llm.polish(draft)
return final优缺点
| 优点 | 缺点 |
|---|---|
| 易于调试,可追踪每步 | 总延迟是各步之和 |
| 每步输出可验证 | 错误可能累积传播 |
| 便于添加检查点 | 不支持并行加速 |
二、路由模式(Routing)
路由模式根据输入特征分类并导向专门的处理流程,确保不同类型的查询得到最优处理。
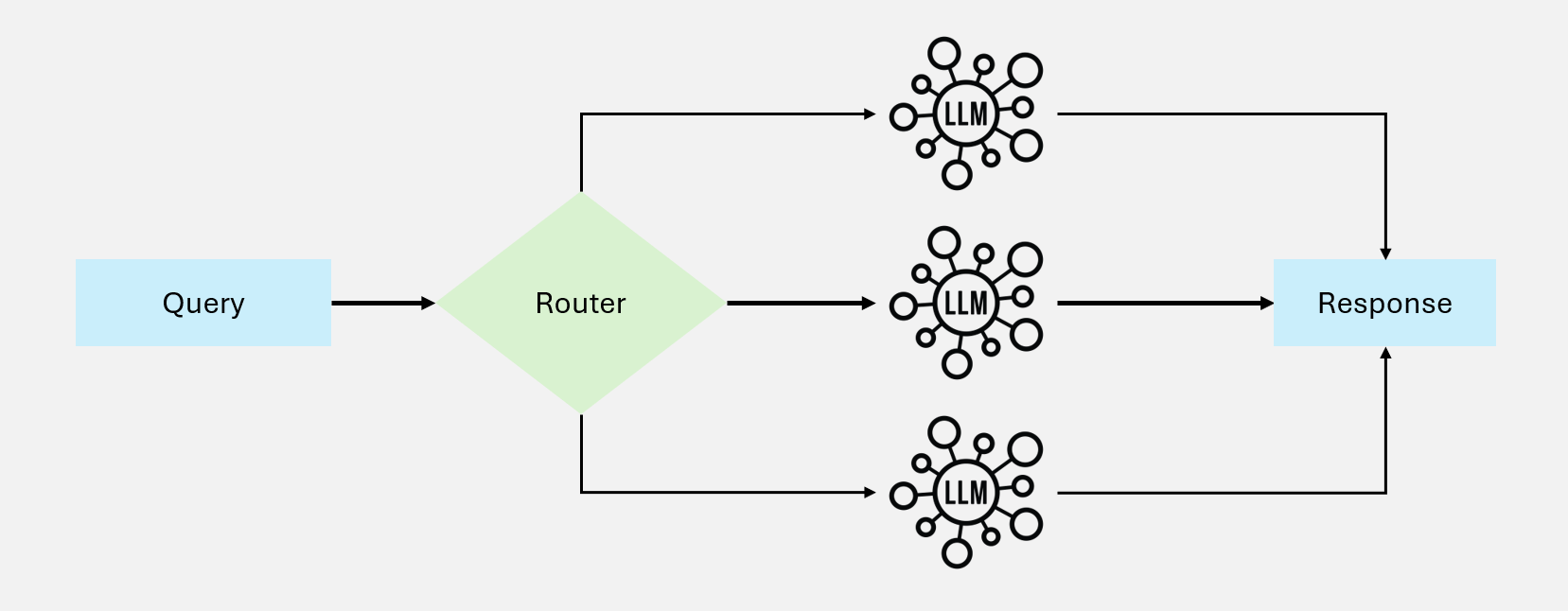 图 2:路由工作流
图 2:路由工作流
工作原理
┌→ 处理流程A(技术问题)
输入 → 分类器 ┼→ 处理流程B(退款申请)
└→ 处理流程C(一般咨询)核心特点
- 输入分类:基于查询特征判断类型
- 专业化处理:不同类型有定制流程
- 资源优化:简单查询用轻量模型
典型应用
1. 客户服务系统
用户查询
│
↓
┌─────────────┐
│ 分类器 │
└─────────────┘
│
├─→ "技术支持" ─→ 技术知识库检索 + 高级模型
│
├─→ "退款处理" ─→ 订单系统 + 退款流程
│
├─→ "产品咨询" ─→ 产品文档 + 标准模型
│
└─→ "其他" ─→ 通用助手2. 成本优化路由
查询复杂度评估
│
├─→ 简单查询 ─→ GPT-3.5 / 小模型(低成本)
│
├─→ 中等查询 ─→ GPT-4o-mini(平衡)
│
└─→ 复杂查询 ─→ GPT-4 / Claude(高性能)实现示例
python
def routing_workflow(query):
# 查询分类
category = classifier.classify(query)
# 根据分类选择处理流程
if category == "technical":
return technical_support_pipeline(query)
elif category == "billing":
return billing_pipeline(query)
elif category == "product":
return product_info_pipeline(query)
else:
return general_assistant(query)三、并行化模式(Parallelization)
并行化将任务分解为独立执行的子任务,同时处理以减少总延迟。
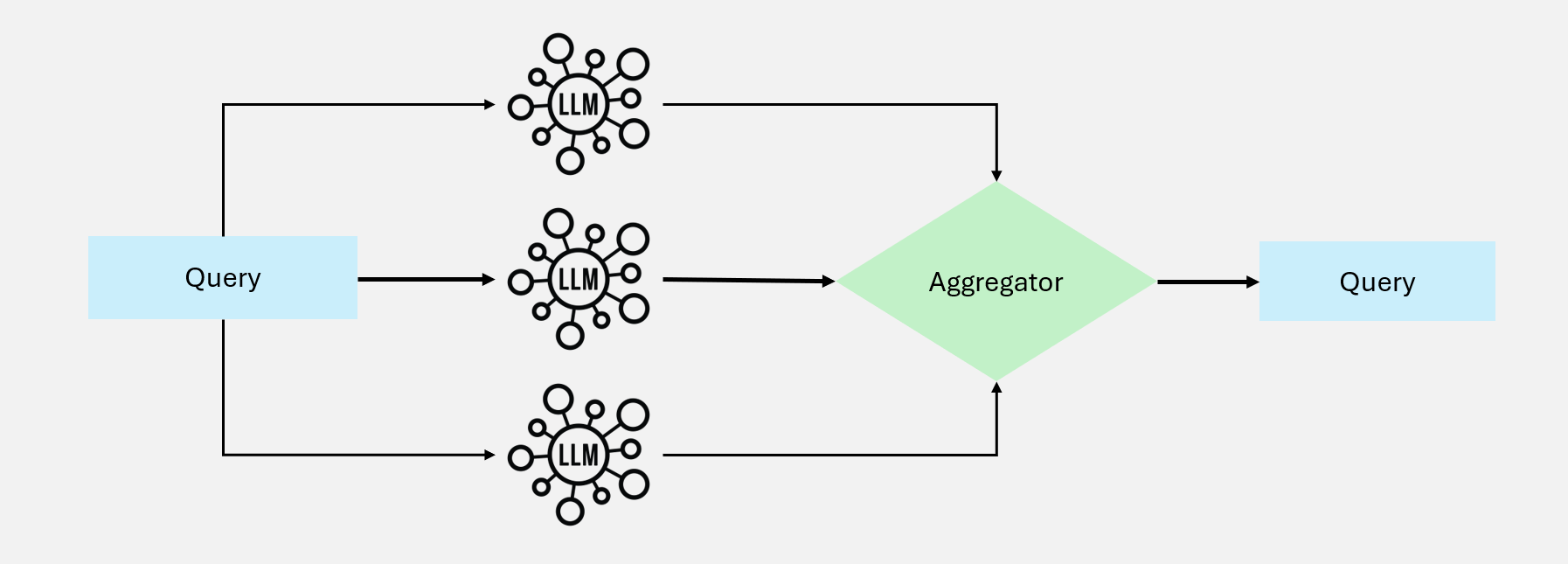 图 3:并行化工作流
图 3:并行化工作流
两种策略
1. 分段(Sectioning)
将任务分解为独立部分,并行处理后合并:
┌→ 子任务A(检索学术文献)──┐
任务 ───┼→ 子任务B(检索新闻资讯)──┼→ 结果合并
└→ 子任务C(检索行业报告)──┘2. 投票(Voting)
多个模型处理同一任务,通过投票或对比提高可靠性:
┌→ 模型A 分析 ──┐
任务 ───┼→ 模型B 分析 ──┼→ 投票/共识
└→ 模型C 分析 ──┘典型应用
分段策略:内容审核系统
用户内容
│
├─→ 安全检测模型(并行)
│
├─→ 情感分析模型(并行)
│
└─→ 响应生成模型(并行)
│
↓
结果合并 → 最终判定投票策略:代码安全审计
代码片段
│
├─→ 模型A:漏洞检测
│
├─→ 模型B:漏洞检测
│
└─→ 模型C:漏洞检测
│
↓
交叉验证 → 高置信度漏洞列表实现示例
python
import asyncio
async def parallel_retrieval(query):
# 定义并行任务
tasks = [
retrieve_academic(query),
retrieve_news(query),
retrieve_industry(query),
retrieve_patents(query)
]
# 并行执行
results = await asyncio.gather(*tasks)
# 合并结果
return merge_results(results)四、编排-工作者模式(Orchestrator-Workers)
该模式由中央编排者动态分配任务给专业工作者,根据输入复杂度自适应调整。
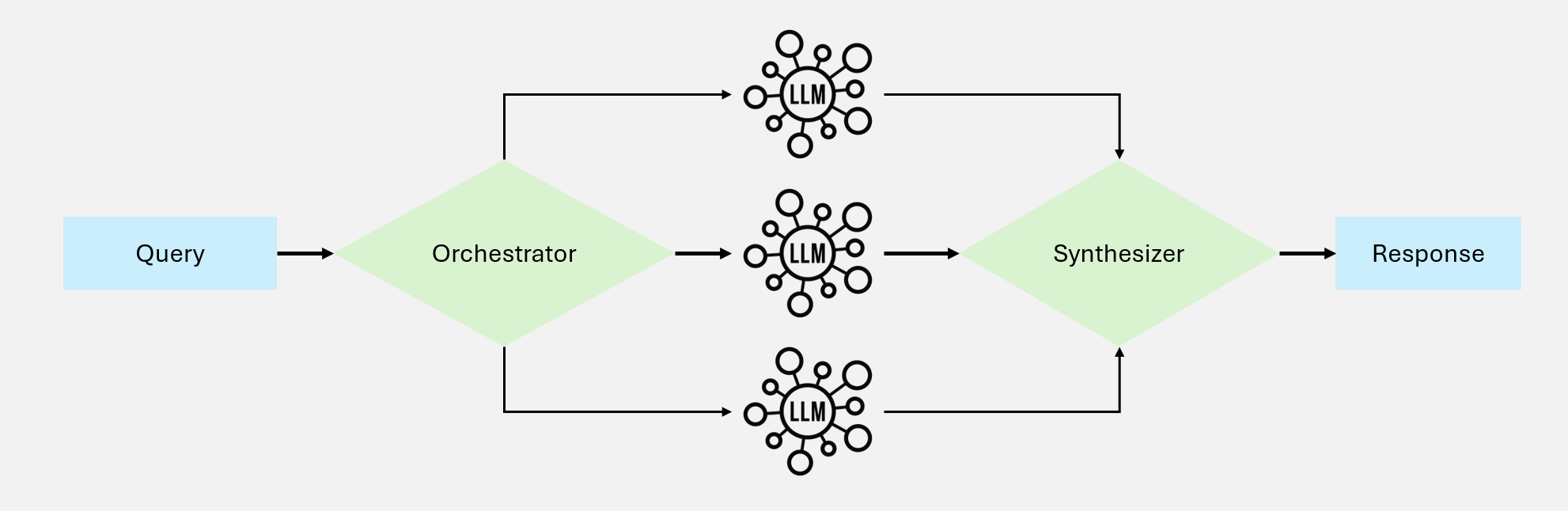 图 4:编排-工作者工作流
图 4:编排-工作者工作流
工作原理
┌─────────────────────┐
│ 编排者 │
│ (Orchestrator) │
└─────────────────────┘
│
┌───────────────┼───────────────┐
↓ ↓ ↓
┌─────────┐ ┌─────────┐ ┌─────────┐
│ 工作者A │ │ 工作者B │ │ 工作者C │
│(检索专家)│ │(分析专家)│ │(写作专家)│
└─────────┘ └─────────┘ └─────────┘
│ │ │
└───────────────┼───────────────┘
↓
结果整合与并行化的区别
| 维度 | 并行化 | 编排-工作者 |
|---|---|---|
| 任务分配 | 预定义 | 动态决定 |
| 子任务数量 | 固定 | 按需变化 |
| 适应性 | 低 | 高 |
| 复杂度 | 简单 | 较复杂 |
典型应用
代码库修改任务
用户需求:"重构用户认证模块,支持 OAuth 2.0"
编排者分析后分配:
├─→ 工作者A:修改 auth.py(认证逻辑)
├─→ 工作者B:修改 config.py(配置项)
├─→ 工作者C:修改 routes.py(路由定义)
├─→ 工作者D:更新 tests/(测试用例)
└─→ 工作者E:更新 docs/(文档)
编排者整合:合并所有修改,验证一致性多源研究任务
研究主题:"新能源汽车市场分析"
编排者动态分配:
├─→ 学术检索工作者:搜索技术论文
├─→ 市场研究工作者:获取行业报告
├─→ 新闻监控工作者:收集最新动态
├─→ 数据分析工作者:处理销量数据
└─→ 可能追加工作者:专利检索(如需)
编排者整合:综合分析报告五、评估-优化模式(Evaluator-Optimizer)
该模式通过评估-反馈-改进的循环,持续提升输出质量。
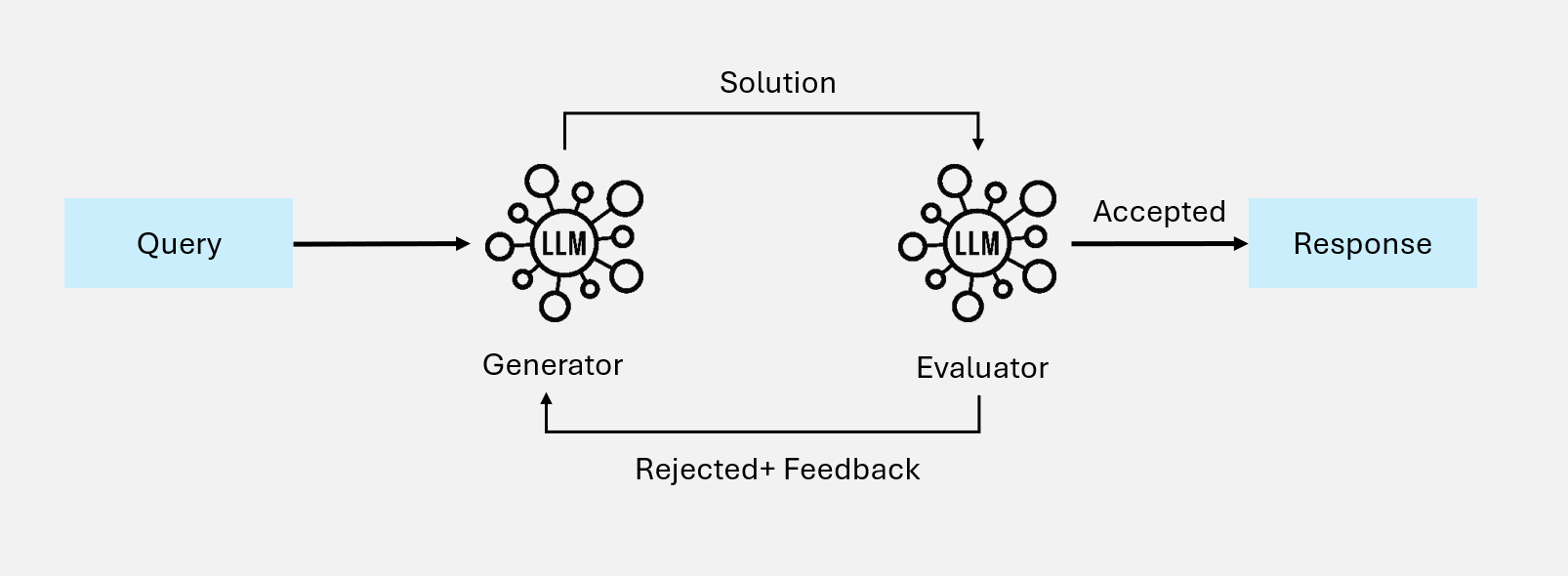 图 5:评估-优化工作流
图 5:评估-优化工作流
工作原理
输入 → 生成器 → 初始输出 → 评估器 → 评分/反馈
↑ │
│ 不满意 │
└────────────────────┘
│
满意
↓
最终输出核心组件
- 生成器(Generator):生成内容的主模型
- 评估器(Evaluator):评估内容质量的模型
- 反馈机制:将评估结果转化为改进指导
- 终止条件:达到质量阈值或最大迭代次数
典型应用
文学翻译优化
原文(英文小说段落)
│
↓
第1轮翻译 → 评估器评分:75/100
│ 反馈:部分习语翻译生硬
↓
第2轮翻译 → 评估器评分:85/100
│ 反馈:语言流畅,但少数细节可优化
↓
第3轮翻译 → 评估器评分:92/100
│ 反馈:达到出版标准
↓
输出最终翻译多轮研究检索
研究问题:"CRISPR 技术的伦理争议"
│
↓
第1轮检索 → 评估:覆盖面不足,缺少法律视角
│
↓
第2轮检索(补充法律文献)→ 评估:缺少最新案例
│
↓
第3轮检索(补充2023-2024案例)→ 评估:全面
│
↓
输出综合报告实现示例
python
def evaluator_optimizer_workflow(task, max_iterations=5, threshold=0.9):
output = generator.generate(task)
for i in range(max_iterations):
# 评估当前输出
score, feedback = evaluator.evaluate(output)
# 检查是否达到阈值
if score >= threshold:
return output
# 基于反馈改进
output = generator.improve(output, feedback)
return output # 返回最佳结果工作流模式选择指南
你的任务是什么类型?
│
┌─────────────────┼─────────────────┐
↓ ↓ ↓
需要高质量输出? 任务可并行? 有多种输入类型?
│ │ │
↓ ↓ ↓
评估-优化模式 并行化模式 路由模式
│
需要动态分配?
│
┌──────┴──────┐
↓ ↓
是:编排-工作者 否:提示链组合使用
实际系统中,多种工作流模式经常组合使用:
用户查询
│
↓
路由(判断查询类型)
│
├─→ 简单查询 → 直接响应
│
└─→ 复杂查询 → 编排-工作者
│
├─→ 并行检索(多数据源)
│
└─→ 评估-优化(质量保证)
│
↓
最终响应思考题
- 在什么情况下,提示链模式比并行化模式更合适?
- 如何设计评估器以避免"评估器偏见"问题?
- 编排-工作者模式中,如何处理工作者失败的情况?