19.2 训练范式与部署
🎯 本节目标
理解 DeepAnalyze 的课程式训练方法、部署方式和多接口支持。
📚 课程式 Agent 训练
核心理念:模拟人类学习过程
DeepAnalyze 采用课程式训练范式(Curriculum-based Training),模拟数据科学家的学习轨迹:
人类数据科学家的学习路径:
│
├── 阶段 1: 学习单项技能
│ ├── 数据清洗
│ ├── 统计分析
│ ├── 可视化
│ └── 报告撰写
│
├── 阶段 2: 整合多项技能
│ └── 完成端到端项目
│
└── 阶段 3: 从反馈中优化
└── 根据用户反馈改进
DeepAnalyze 的训练范式:
│
├── Phase 1: 单能力 SFT (Single-ability SFT)
│ └── 分别训练各项数据科学能力
│
├── Phase 2: 多能力冷启动 (Multi-ability Cold Start)
│ └── 整合能力,形成基础 Agent
│
└── Phase 3: 强化学习优化 (Reinforcement Learning)
└── 使用 SkyRL 优化决策训练阶段详解
Phase 1: 单能力微调
bash
# 使用 ms-swift 进行单能力 SFT
# scripts/single.sh
CUDA_VISIBLE_DEVICES=0,1,2,3 swift sft \
--model_type deepseek-r1-qwen3-8b \
--dataset data/single_ability_data.jsonl \
--output_dir checkpoints/single_ability \
--num_train_epochs 3 \
--per_device_train_batch_size 2 \
--gradient_accumulation_steps 8 \
--learning_rate 2e-5 \
--max_length 8192单能力数据格式:
json
{
"instruction": "分析以下数据集的基本统计信息",
"input": "数据文件: sales_data.csv",
"output": "<Analyze>正在加载数据...</Analyze>\n<Code>\nimport pandas as pd\ndf = pd.read_csv('sales_data.csv')\nprint(df.describe())\n</Code>"
}Phase 2: 多能力冷启动
bash
# 使用 ms-swift 进行多能力冷启动
# scripts/multi_coldstart.sh
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 swift sft \
--model_type deepseek-r1-qwen3-8b \
--resume_from checkpoints/single_ability \
--dataset data/multi_ability_data.jsonl \
--output_dir checkpoints/multi_coldstart \
--num_train_epochs 2 \
--per_device_train_batch_size 1 \
--gradient_accumulation_steps 16 \
--learning_rate 1e-5 \
--max_length 32768多能力数据格式:
json
{
"instruction": "对客户数据进行完整分析,包括数据清洗、可视化和报告生成",
"input": "数据文件: customers.csv, orders.csv, products.csv",
"output": "<Analyze>开始端到端分析流程...</Analyze>\n<Code>...</Code>\n<Execute>...</Execute>\n<Understand>...</Understand>\n<Code>...</Code>\n<Answer>## 分析报告\n...</Answer>"
}Phase 3: 强化学习优化
bash
# 使用 SkyRL 进行强化学习
# scripts/multi_rl.sh
python -m skyrl.train \
--model_path checkpoints/multi_coldstart \
--reward_model reward/deepanalyze_reward \
--algorithm ppo \
--num_epochs 1 \
--batch_size 64 \
--learning_rate 1e-6 \
--output_dir checkpoints/deepanalyze-8b📊 训练数据:DataScience-Instruct-500K
数据集概览
| 属性 | 值 |
|---|---|
| 名称 | DataScience-Instruct-500K |
| 样本数 | ~500,000 |
| 来源 | 数据驱动的轨迹合成 |
| 格式 | JSONL |
| 许可 | 开源 |
数据合成流程
数据合成框架
│
├── 1. 种子任务收集
│ ├── 真实数据科学任务
│ ├── Kaggle 竞赛
│ └── 学术论文案例
│
├── 2. 任务扩展
│ ├── LLM 生成变体
│ ├── 参数化模板
│ └── 领域适配
│
├── 3. 轨迹生成
│ ├── 使用强大 LLM 生成解决方案
│ ├── 执行代码验证正确性
│ └── 人工审核关键样本
│
└── 4. 质量过滤
├── 代码可执行性检查
├── 输出正确性验证
└── 多样性去重数据示例
json
{
"id": "ds_001234",
"task_type": "exploratory_analysis",
"instruction": "请分析这份销售数据,找出季度销售趋势和top 10畅销产品",
"files": [
{"name": "sales_2024.csv", "description": "2024年销售记录"},
{"name": "products.csv", "description": "产品信息表"}
],
"conversation": [
{
"role": "user",
"content": "请分析这份销售数据..."
},
{
"role": "assistant",
"content": "<Analyze>开始分析销售数据...</Analyze>\n<Code>\nimport pandas as pd\nimport matplotlib.pyplot as plt\n\n# 加载数据\nsales = pd.read_csv('sales_2024.csv')\nproducts = pd.read_csv('products.csv')\n\n# 季度销售趋势\nsales['date'] = pd.to_datetime(sales['date'])\nsales['quarter'] = sales['date'].dt.quarter\nquarterly = sales.groupby('quarter')['amount'].sum()\nprint(quarterly)\n</Code>"
},
{
"role": "execute",
"content": "<Execute>\nquarter\n1 1234567.89\n2 1456789.12\n3 1678901.23\n4 1890123.45\nName: amount, dtype: float64\n</Execute>"
},
{
"role": "assistant",
"content": "<Understand>销售额逐季度增长,Q4 最高...</Understand>\n<Code>\n# 可视化季度趋势\nplt.figure(figsize=(10, 6))\nplt.bar(quarterly.index, quarterly.values)\nplt.title('2024年季度销售趋势')\nplt.xlabel('季度')\nplt.ylabel('销售额')\nplt.savefig('quarterly_trend.png')\nprint('图表已保存')\n</Code>"
},
{
"role": "execute",
"content": "<Execute>图表已保存</Execute>"
},
{
"role": "assistant",
"content": "<Answer>\n## 销售数据分析报告\n\n### 1. 季度销售趋势\n...\n\n### 2. Top 10 畅销产品\n...\n</Answer>"
}
]
}🚀 部署方式
方式一:直接使用 vLLM
bash
# 启动 vLLM 服务
vllm serve RUC-DataLab/DeepAnalyze-8B \
--port 8000 \
--tensor-parallel-size 1 \
--max-model-len 131072 \
--trust-remote-code
# 或使用量化版本(16GB 显存)
vllm serve RUC-DataLab/DeepAnalyze-8B \
--port 8000 \
--quantization awq \
--kv-cache-dtype fp8 \
--max-model-len 32768方式二:Docker 部署
dockerfile
# docker/Dockerfile
FROM nvidia/cuda:12.1-devel-ubuntu22.04
# 安装依赖
RUN pip install vllm>=0.8.5 fastapi uvicorn
# 复制代码
COPY . /app
WORKDIR /app
# 启动服务
CMD ["python", "-m", "API.main"]bash
# 构建并运行
docker build -t deepanalyze:latest -f docker/Dockerfile .
docker run -d --gpus all -p 8000:8000 -p 4000:4000 deepanalyze:latest方式三:Python 直接调用
python
from deepanalyze import DeepAnalyzeVLLM
# 初始化
analyzer = DeepAnalyzeVLLM(
checkpoint_path="RUC-DataLab/DeepAnalyze-8B"
)
# 执行分析
result = analyzer.generate(
prompt="分析 data.csv 中的销售趋势",
workspace="/path/to/data/"
)
print(result["answer"])🖥️ 多接口支持
1. Web UI(推荐)
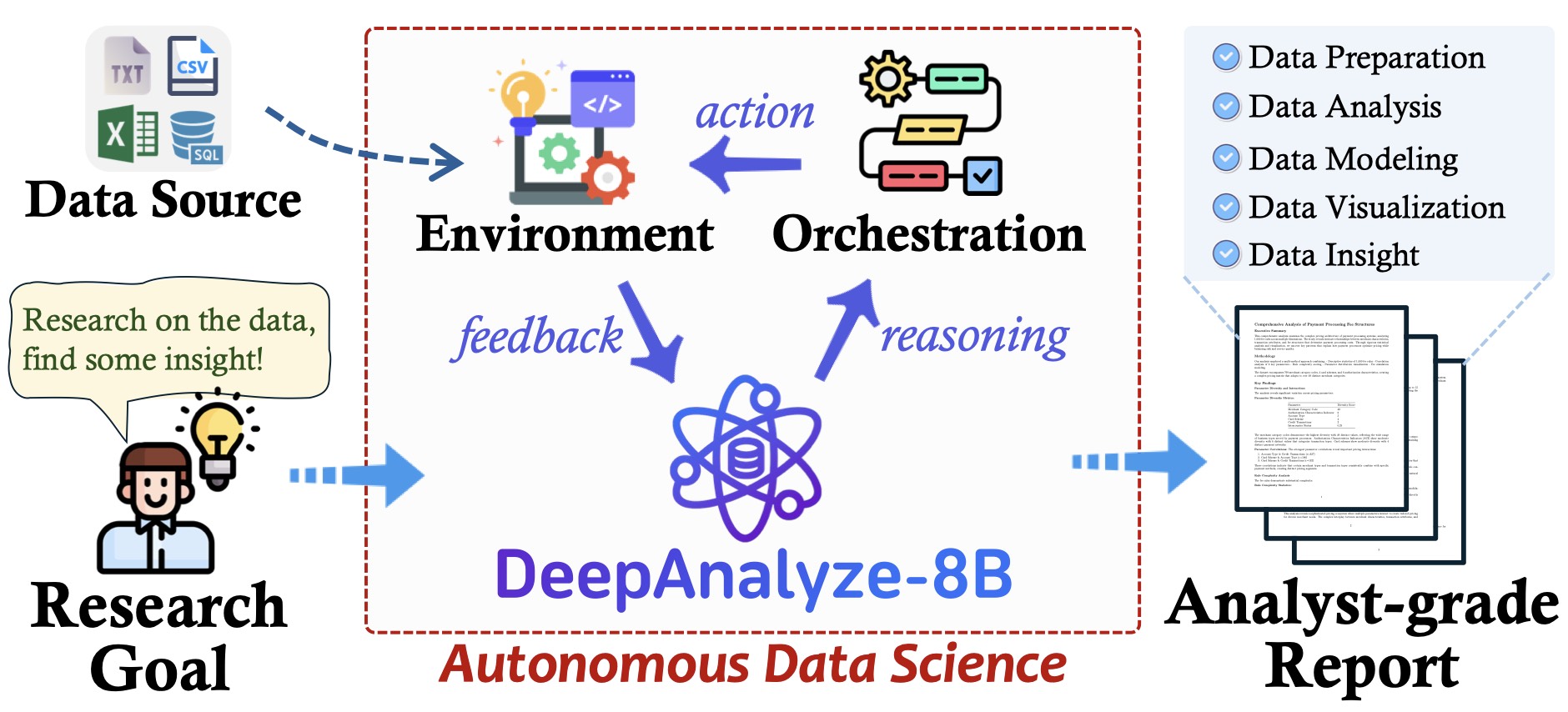
图:DeepAnalyze Web UI 界面
bash
# 启动 Web UI
cd demo/chat
# 安装前端依赖
cd frontend && npm install && npm run build
# 启动后端
cd ../backend && python main.py
# 访问 http://localhost:4000功能特点:
- 📁 文件上传和管理
- 💬 对话式交互
- 📊 代码执行可视化
- 📄 报告预览和导出
2. Jupyter 集成(MCP)
bash
# 启动 Jupyter MCP Server
cd demo/jupyter
python mcp_server.py
# 在 Jupyter 中使用python
# Jupyter Notebook 中
from deepanalyze_jupyter import analyze
# 直接分析当前 notebook 中的数据
result = analyze("分析 df 变量中的数据分布")3. CLI 命令行
bash
# 使用 CLI
cd demo/cli
python cli.py --prompt "分析 data.csv" --workspace /data/
# 交互模式
python cli.py --interactive4. OpenAI 兼容 API
bash
# 启动 API 服务
cd API
python start_server.py --port 8080python
# 使用 OpenAI SDK 调用
from openai import OpenAI
client = OpenAI(
base_url="http://localhost:8080/v1",
api_key="dummy" # 本地服务不需要真实 key
)
response = client.chat.completions.create(
model="deepanalyze-8b",
messages=[
{"role": "user", "content": "分析 sales.csv 的销售趋势"}
]
)
print(response.choices[0].message.content)⚙️ 量化与优化
量化配置
python
# quantize.py
from transformers import AutoModelForCausalLM
from awq import AutoAWQForCausalLM
# 加载模型
model_path = "RUC-DataLab/DeepAnalyze-8B"
# AWQ 4-bit 量化
model = AutoAWQForCausalLM.from_pretrained(model_path)
model.quantize(
tokenizer=tokenizer,
quant_config={
"zero_point": True,
"q_group_size": 128,
"w_bit": 4
}
)
# 保存量化模型
model.save_quantized("deepanalyze-8b-awq")显存优化策略
| 策略 | 显存需求 | 性能影响 | 适用场景 |
|---|---|---|---|
| FP16 | 24GB+ | 无 | 高端 GPU |
| AWQ 4-bit | 16GB | 轻微 | 消费级 GPU |
| FP8 KV Cache | 再减 20% | 轻微 | 长上下文 |
| Tensor Parallel | 分摊到多卡 | 无 | 多 GPU |
bash
# 16GB 显存配置
vllm serve RUC-DataLab/DeepAnalyze-8B \
--quantization awq \
--kv-cache-dtype fp8 \
--max-model-len 32768 \
--gpu-memory-utilization 0.95📈 性能基准
数据科学任务评测
| 任务类型 | 成功率 | 平均耗时 |
|---|---|---|
| 数据探索 | 95% | 30s |
| 统计分析 | 92% | 45s |
| 可视化 | 88% | 60s |
| 报告生成 | 85% | 120s |
| 端到端分析 | 78% | 300s |
与基线对比
| 方法 | 端到端成功率 | 报告质量 |
|---|---|---|
| GPT-4 + 工作流 Agent | 65% | 良好 |
| Claude + ReAct | 70% | 良好 |
| DeepAnalyze-8B | 78% | 优秀 |
| DeepAnalyze-8B (量化) | 75% | 良好 |
🔧 常见问题
Q1: 如何处理 CUDA 内存不足?
bash
# 方案 1: 使用量化
vllm serve ... --quantization awq
# 方案 2: 减少上下文长度
vllm serve ... --max-model-len 16384
# 方案 3: 降低并发
vllm serve ... --max-num-seqs 4Q2: 如何添加自定义数据源?
python
# 将文件放入 workspace 目录
workspace = "/path/to/analysis/"
# 复制数据文件到 workspace
shutil.copy("my_data.csv", workspace)
# 执行分析
result = analyzer.generate(
prompt="分析 my_data.csv",
workspace=workspace
)Q3: 如何导出分析报告?
python
# 生成报告
result = analyzer.generate(prompt, workspace)
# 保存为 Markdown
with open("report.md", "w") as f:
f.write(result["answer"])
# 转换为 PDF(需要 pandoc)
import subprocess
subprocess.run(["pandoc", "report.md", "-o", "report.pdf"])接下来: 19.3 实战案例