19.0 本章介绍
首个自主数据科学的 Agentic LLM
欢迎来到 DeepAnalyze 的世界
在前面的模块中,我们系统学习了 LangGraph 的核心概念和各种 Agent 设计模式。现在,让我们深入研究一个完全不使用 LangGraph 的 Agent 框架 —— DeepAnalyze。
通过对比不同的 Agent 实现方式,我们能更深刻地理解 Agent 的本质。
🎯 这是一个与众不同的项目
DeepAnalyze 是由中国人民大学(RUC DataLab)和清华大学的研究团队开发的首个自主数据科学 Agentic LLM,发表于 arXiv(论文编号:2510.16872)。
它的独特之处在于:
| 维度 | DeepAnalyze | 其他方案(如 LangGraph Agent) |
|---|---|---|
| 框架依赖 | ❌ 完全自研 | ✅ 依赖 LangChain/LangGraph |
| LLM 选择 | 专用微调模型(8B) | 通用 API(GPT-4/Claude) |
| 训练方式 | SFT + 强化学习 | 无训练,Prompt Engineering |
| 推理引擎 | vLLM 本地部署 | OpenAI/Anthropic API |
| 专业领域 | 数据科学专用 | 通用任务 |
🔍 核心发现:自研 Agent 框架
关键结论:DeepAnalyze 没有使用任何现成的 Agent 框架
通过深入分析源代码,我们发现 DeepAnalyze 的 Agent 架构是完全自主搭建的:
DeepAnalyze Agent 架构
├── 推理引擎: vLLM(高性能本地推理)
├── Agent 循环: 自研的迭代推理系统
├── 代码执行: 自研的沙箱执行器
├── 标签系统: 自定义的 XML 标签协议
└── 训练框架: ms-swift (SFT) + SkyRL (RL)没有使用:
- ❌ LangChain
- ❌ LangGraph
- ❌ AutoGen
- ❌ CrewAI
- ❌ 其他现成 Agent 框架
为什么选择自研?
自研 Agent 框架的优势:
├── 完全控制推理流程
├── 可以针对数据科学任务深度优化
├── 训练与推理紧密集成
├── 无第三方依赖的版本问题
└── 更高的执行效率🏗️ 系统架构全景
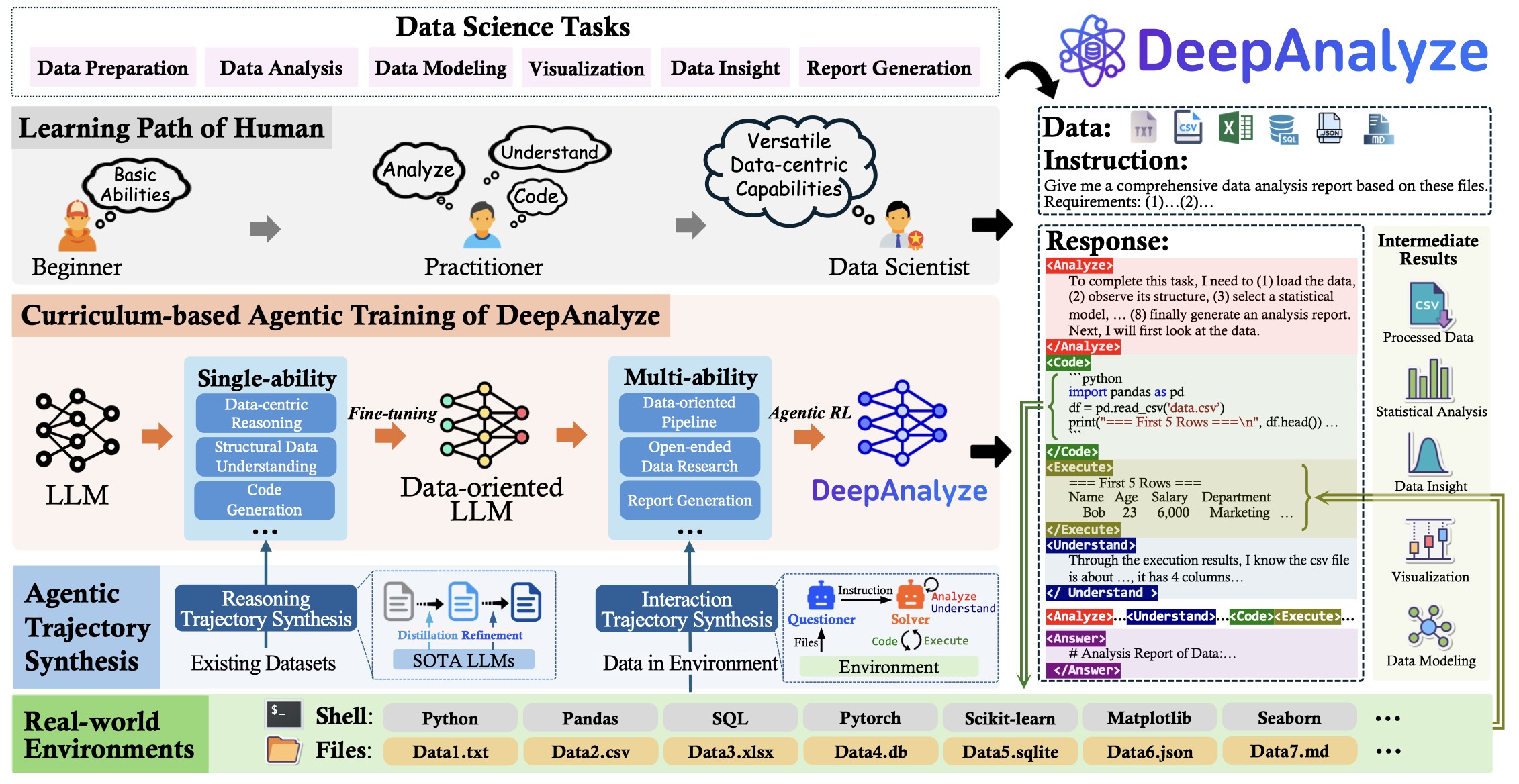
图:DeepAnalyze 系统架构
核心组件
┌─────────────────────────────────────────────────────────────┐
│ DeepAnalyze System │
├─────────────────────────────────────────────────────────────┤
│ ┌─────────────┐ ┌─────────────┐ ┌─────────────────────┐ │
│ │ Web UI │ │ Jupyter │ │ CLI / API │ │
│ │ (Next.js) │ │ (MCP) │ │ (FastAPI) │ │
│ └──────┬──────┘ └──────┬──────┘ └──────────┬──────────┘ │
│ │ │ │ │
│ └────────────────┼─────────────────────┘ │
│ │ │
│ ┌─────▼─────┐ │
│ │ vLLM │ │
│ │ Engine │ │
│ └─────┬─────┘ │
│ │ │
│ ┌─────▼─────┐ │
│ │ DeepSeek │ │
│ │ R1-Qwen3 │ │
│ │ 8B │ │
│ └───────────┘ │
└─────────────────────────────────────────────────────────────┘技术栈一览
| 层级 | 技术选型 | 说明 |
|---|---|---|
| 前端 | Next.js + TypeScript | 现代化 Web UI |
| 后端 API | FastAPI + Python | OpenAI 兼容的 API |
| 推理引擎 | vLLM (v0.8.5+) | 高性能 LLM 服务 |
| 基座模型 | DeepSeek-R1-0528-Qwen3-8B | 8B 参数专用模型 |
| 训练框架 | ms-swift + SkyRL | SFT + RL 训练 |
| Jupyter 集成 | MCP Server | 无缝笔记本体验 |
🔄 Agent 循环机制:与 LangGraph 的对比
DeepAnalyze 的自研 Agent 循环
python
# 核心 Agent 循环逻辑(简化版)
class DeepAnalyzeVLLM:
def generate(self, prompt, workspace):
messages = [{"role": "user", "content": prompt}]
for round in range(30): # 最多 30 轮迭代
# 1. 调用 vLLM 推理
response = self.call_vllm(messages)
# 2. 检测是否有 <Code> 标签
code_blocks = self.extract_code(response)
# 3. 如果有代码,执行并获取结果
if code_blocks:
for code in code_blocks:
result = self.execute_code(code, workspace)
messages.append({
"role": "execute",
"content": f"<Execute>{result}</Execute>"
})
# 4. 检测是否有 <Answer> 标签
if "<Answer>" in response:
return self.extract_answer(response)
messages.append({"role": "assistant", "content": response})
return "Max rounds reached"与 LangGraph ReAct Agent 的对比
| 维度 | DeepAnalyze | LangGraph ReAct |
|---|---|---|
| 循环控制 | 简单 for 循环(最多 30 轮) | 图结构 + 条件边 |
| 状态管理 | 消息列表 + 文件系统 | TypedDict State |
| 工具调用 | <Code> 标签触发 | tool_calls API |
| 终止条件 | <Answer> 标签 | 条件边路由到 END |
| 可观测性 | 手动日志 | 内置 Trace/Debug |
| 持久化 | 文件系统 | Checkpointer |
| 错误处理 | try-except + 重试 | RetryPolicy |
| 人工介入 | 无原生支持 | interrupt() API |
代码风格对比
DeepAnalyze 风格(命令式循环):
python
for round in range(max_rounds):
response = llm.generate(messages)
if has_code(response):
result = execute(response)
messages.append(result)
if has_answer(response):
return extract_answer(response)LangGraph 风格(声明式图):
python
graph = StateGraph(State)
graph.add_node("agent", call_llm)
graph.add_node("tools", execute_tools)
graph.add_conditional_edges(
"agent",
should_continue,
{"continue": "tools", "end": END}
)
graph.add_edge("tools", "agent")🏷️ 自定义标签协议
DeepAnalyze 使用自定义 XML 标签来标识不同类型的输出:
xml
<!-- 分析过程 -->
<Analyze>
对数据进行初步探索...
</Analyze>
<!-- 理解阶段 -->
<Understand>
数据包含 10 个文件,主要是关于学生贷款的...
</Understand>
<!-- 代码执行 -->
<Code>
import pandas as pd
df = pd.read_csv('data.csv')
print(df.head())
</Code>
<!-- 执行结果 -->
<Execute>
col1 col2 col3
0 1 2 3
1 4 5 6
</Execute>
<!-- 最终答案 -->
<Answer>
## 分析报告
根据数据分析,我们发现...
</Answer>这种标签协议的设计:
- ✅ 简单直观,易于解析
- ✅ 结构化输出,便于后处理
- ✅ 与模型训练紧密结合
- ❌ 不如 LangGraph 的工具调用灵活
- ❌ 无法动态注册新工具
📊 训练范式:课程式 Agent 训练
DeepAnalyze 的独特之处在于其课程式训练范式(Curriculum-based Training):
训练阶段
│
├── Phase 1: 单能力微调 (Single-ability SFT)
│ ├── 数据准备能力
│ ├── 统计分析能力
│ ├── 可视化能力
│ └── 报告生成能力
│
├── Phase 2: 多能力冷启动 (Multi-ability Cold Start)
│ └── 整合多种能力,形成基础 Agent
│
└── Phase 3: 强化学习优化 (Reinforcement Learning)
└── 使用 SkyRL 进一步优化决策训练数据规模:
- 数据集名称:DataScience-Instruct-500K
- 样本数量:50 万条
- 数据来源:数据驱动的轨迹合成
🎯 与 LangGraph 的深度对比
设计哲学对比
| 维度 | DeepAnalyze | LangGraph |
|---|---|---|
| 核心理念 | 端到端训练的专用 Agent | 声明式编排的通用框架 |
| 适用场景 | 数据科学专用 | 任意 LLM 应用 |
| 技术门槛 | 需要训练基础设施 | 仅需 API Key |
| 可扩展性 | 需要重新训练 | 添加工具/节点即可 |
| 成本模型 | 一次训练,低推理成本 | 按 API 调用付费 |
适用场景分析
选择 DeepAnalyze 当你需要:
- ✅ 专业的数据科学分析能力
- ✅ 本地部署,数据不出域
- ✅ 低延迟、高吞吐的推理
- ✅ 完全可控的模型行为
选择 LangGraph 当你需要:
- ✅ 快速原型开发
- ✅ 灵活的工具集成
- ✅ 多种 LLM 后端支持
- ✅ 复杂的多 Agent 协作
- ✅ 人工介入和状态持久化
📖 你将学到什么?
核心知识点
自研 Agent 框架的设计
- 迭代推理循环的实现
- 代码执行沙箱的构建
- 自定义标签协议的设计
vLLM 推理引擎集成
- 模型部署与服务化
- API 兼容层的实现
- 量化与性能优化
课程式 Agent 训练
- 能力分解与阶段训练
- SFT 与 RL 的结合
- 训练数据的构建
多接口部署
- Web UI 的实现
- Jupyter 集成(MCP)
- OpenAI 兼容 API
实战技能
- ✅ 理解不依赖框架的 Agent 实现
- ✅ 掌握 vLLM 的部署与使用
- ✅ 学习专用领域 Agent 的训练方法
- ✅ 对比不同 Agent 架构的优劣
🗺️ 章节导航
本章共 5 节,循序渐进地剖析 DeepAnalyze:
第一部分:概览与架构 (19.0-19.1)
- 19.0 本章介绍:项目概述与框架对比(当前页)
- 19.1 Agent 架构深度解析:自研框架的核心实现
第二部分:核心实现 (19.2-19.3)
- 19.2 训练范式与数据:课程式训练的方法论
- 19.3 部署与接口:多种部署方式详解
第三部分:实践与总结 (19.4-19.5)
- 19.4 实战案例:端到端数据分析演示
- 19.5 本章小结:核心要点与对比总结
⚙️ 环境要求
GPU 内存需求
| 配置 | 显存要求 | 说明 |
|---|---|---|
| 最低配置 | 16GB | 4-bit 量化 + FP8 KV Cache |
| 推荐配置 | 24GB | 原始模型 + 扩展上下文 |
| 最佳配置 | 80GB | 完整精度,最佳性能 |
基础依赖
bash
# 安装 vLLM
pip install vllm>=0.8.5
# 安装 DeepAnalyze
pip install -r requirements.txt🔗 资源链接
| 资源 | 链接 |
|---|---|
| GitHub 仓库 | ruc-datalab/DeepAnalyze |
| HuggingFace 模型 | RUC-DataLab/DeepAnalyze-8B |
| 训练数据集 | DataScience-Instruct-500K |
| arXiv 论文 | 2510.16872 |
🚀 准备好了吗?
DeepAnalyze 展示了一种与 LangGraph 完全不同的 Agent 实现方式。通过学习这个项目,你将:
- 理解 Agent 框架的本质,而不只是使用框架
- 掌握端到端训练 Agent 的方法论
- 学会如何为特定领域构建专用 Agent
- 对比不同技术路线的优劣
让我们开始这段探索之旅!
接下来: 19.1 Agent 架构深度解析