Agentic RAG 概述
本章节综合整理自论文 Agentic Retrieval-Augmented Generation: A Survey on Agentic RAG 及业界实践经验
引言:重新思考 RAG
在深入 Agentic RAG 之前,我们需要先理解一个关键问题:什么时候需要 RAG,什么时候不需要?
一个反直觉的案例
当 AI 编程助手都在比拼谁的索引更智能时,Claude Code 选择了每次都实时搜索、不保留任何状态——直接使用 grep 和 glob 这些经典的 Unix 工具。
这个看似"倒退"的选择引发了争议。有人认为这是"一步烂棋",会"烧掉太多 tokens"。但 Anthropic 团队的结论却是:
"测试了 RAG 等多种方案后,选择了 agentic search——使用 grep、glob 的常规代码搜索。这种方式在性能上大幅超越了所有其他方案。"
这告诉我们什么?
RAG 不是银弹。 在某些场景下,简单的实时搜索比复杂的向量索引更有效。理解这一点,恰恰是掌握 Agentic RAG 的关键——不是盲目应用 RAG,而是让智能体自主判断何时需要检索、用什么方式检索。
这就是 Agentic RAG 的核心思想:赋予系统决策能力,而不是固守单一的检索模式。
什么是 Agentic RAG?
Agentic RAG 是检索增强生成(RAG)技术的最新演进形态。它将自主智能体(Autonomous Agents) 引入传统 RAG 系统,使系统具备了动态决策、迭代推理和自适应检索的能力。
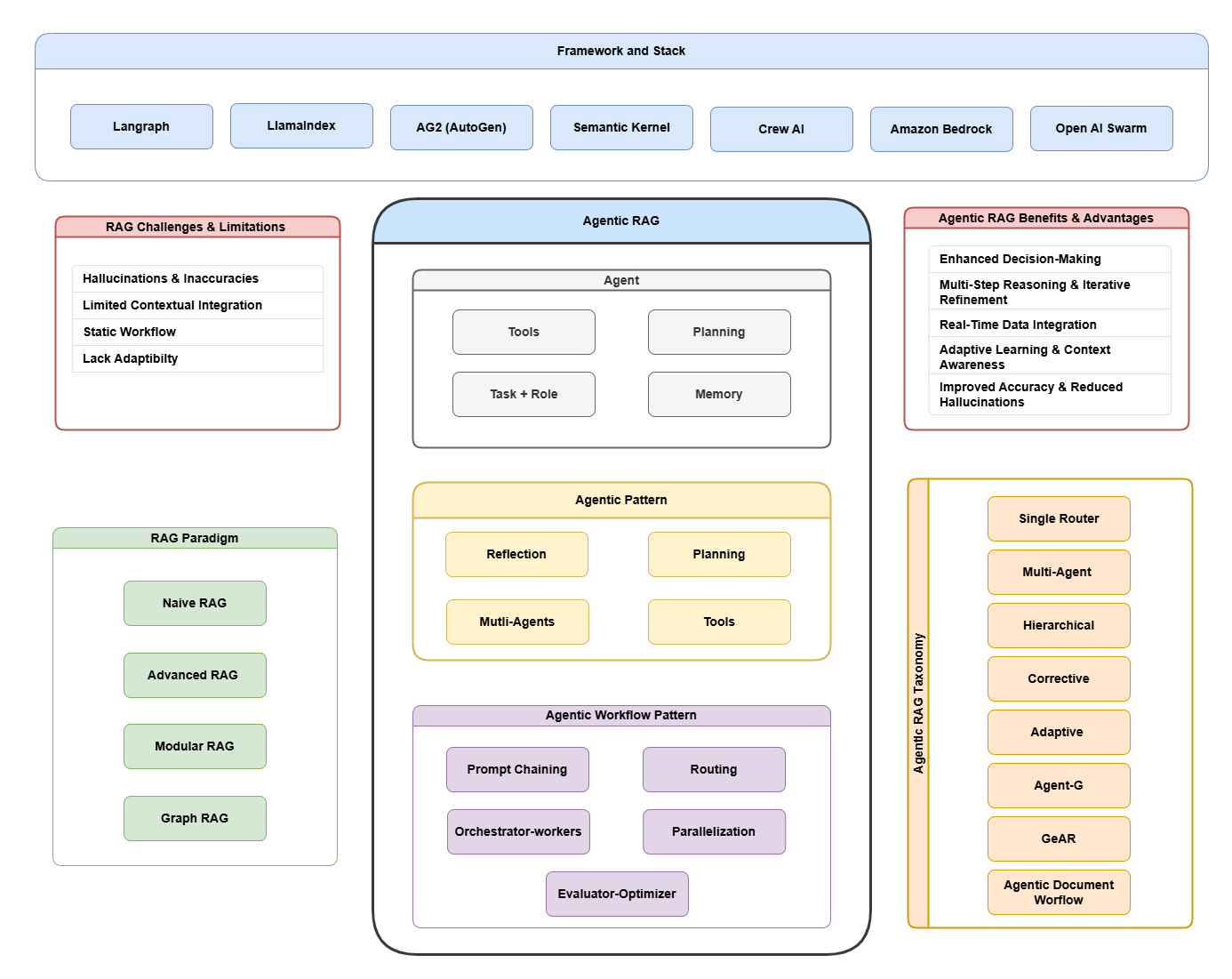 图 1:Agentic RAG 技术全景图
图 1:Agentic RAG 技术全景图
为什么需要 Agentic RAG?
传统 RAG 的局限性
传统 RAG 系统虽然解决了 LLM 知识时效性的问题,但仍存在以下核心挑战:
| 挑战 | 具体问题 |
|---|---|
| 上下文整合困难 | 静态检索流程难以将检索到的信息无缝整合到生成过程中 |
| 多步推理受限 | 无法基于中间结果迭代优化检索,难以处理需要多轮信息整合的复杂查询 |
| 可扩展性不足 | 查询大规模数据集时计算密集,导致延迟增加,影响实时应用 |
| 确定性缺失 | 向量检索结果难以调试——是嵌入质量?语义偏差?还是索引过期? |
| 维护成本 | 索引需要持续更新,存在"索引卡住"、"缓存损坏"等问题 |
不同检索策略的对比
在选择检索策略时,需要根据具体场景权衡:
| 方案 | 适用场景 | 优势 | 局限 |
|---|---|---|---|
| 向量索引 (RAG) | 语义搜索、模糊查询 | 理解"用户认证"找到 login、authenticate | 需要预处理、维护索引、调试困难 |
| 传统索引 | 精确匹配、代码导航 | 可靠的重构、精确的类型检查 | 构建耗时、资源占用 |
| 实时搜索 | 确定性查询、简单场景 | 零配置、可预测、无维护成本 | 语义理解弱、大规模数据性能下降 |
| Agentic Search | 复杂任务、动态需求 | 智能体自主选择最佳策略 | 需要良好的编排设计 |
Agentic RAG 的解决方案
Agentic RAG 的核心不是固守某种检索方式,而是让智能体动态决策:
传统 RAG:用户查询 → 检索 → 生成 → 响应(单次、静态)
Agentic RAG:用户查询 → 智能体分析 → 动态检索 → 评估反馈 → 迭代优化 → 响应
↑_______________|(循环改进)智能体可以决定:
- 是否需要检索:简单问题直接用 LLM 知识回答
- 用什么方式检索:向量搜索、关键词匹配、还是 API 调用
- 检索结果够不够:不满意就重写查询,继续搜索
Agentic RAG 的核心特征
1. 动态决策能力
智能体能够实时评估查询复杂度,选择最合适的处理策略:
- 简单查询:直接使用 LLM 内置知识
- 中等查询:单次检索即可解决
- 复杂查询:启动多步迭代推理
2. 迭代优化机制
系统能够自我评估和纠错:
- 检索结果不满意时,自动重写查询
- 生成内容存在问题时,触发自我反思
- 多轮优化直到达到质量阈值
3. 多智能体协作
复杂任务可以分解并行处理:
- 专门的检索智能体负责不同数据源
- 评估智能体验证检索质量
- 合成智能体整合多源信息
4. 工具集成能力
智能体可以灵活调用外部工具:
- 向量数据库(语义检索)
- 知识图谱(关系推理)
- Web 搜索(实时信息)
- API 接口(专业数据)
Agentic RAG 与传统 RAG 对比
| 维度 | 传统 RAG | Agentic RAG |
|---|---|---|
| 工作流程 | 固定、线性 | 动态、自适应 |
| 决策方式 | 预设规则 | 智能体自主判断 |
| 错误处理 | 无纠错机制 | 自我反思与迭代 |
| 扩展性 | 受限于预设管道 | 模块化、可扩展 |
| 复杂查询 | 处理困难 | 多步推理支持 |
| 资源效率 | 统一处理 | 按需分配 |
深入思考:有状态 vs 无状态
理解 Agentic RAG,需要思考一个更深层的问题:状态管理。
什么是状态?
用两个简单的例子说明:
# 有状态的计数器 - 像记账本,输出依赖历史
counter = 0
def count():
global counter
counter += 1 # 每次调用在之前基础上累加
return counter
# 第一次返回 1,第二次返回 2...
# 无状态的加法器 - 输出只取决于输入
def add(a, b):
return a + b # 给定 2 和 3,结果永远是 5用数学公式表达:
- 无状态:
Output = f(Input) - 有状态:
Output = f(Input, History)
为什么这与 RAG 相关?
传统 RAG 是有状态的:
- 需要预先构建和维护索引
- 索引状态可能过期、损坏
- 调试困难(索引状态不透明)
Agentic 方法可以选择无状态检索:
- 每次搜索都是全新开始
- 结果完全可预测、可调试
- 无维护成本
无状态设计的四大优势
| 优势 | 说明 | 示例 |
|---|---|---|
| 可组合性 | 工具可以像乐高积木一样自由组合 | `grep error |
| 并行能力 | 无共享状态,天然支持并行 | 16 核并行搜索:42秒 → 3.8秒 |
| 简单性 | 无需生命周期管理 | 无启动/关闭/恢复流程 |
| 可测试性 | 相同输入永远产生相同输出 | 测试失败必是逻辑错误 |
混合策略:现实世界的智慧
最佳实践不是极端,而是权衡。
一个判断标准:"如果系统崩溃重启,用户能接受从零开始吗?"
| 场景 | 答案 | 策略 |
|---|---|---|
| 搜索崩溃了 | 重新搜索就行 | 无状态 |
| 购物车崩溃了 | 商品丢失不可接受 | 有状态 |
| 检索中间结果 | 可以重新检索 | 无状态 |
| 对话上下文 | 需要保持连贯 | 有状态 |
Agentic RAG 的智慧:在正确的地方、以正确的方式管理必要的状态。
- 无状态的检索层:每次搜索独立执行
- 有状态的对话层:保持上下文连贯
- 有状态的记忆层:持久化重要信息
典型应用场景
Agentic RAG 在以下领域展现出显著优势:
企业知识管理
- 跨多个知识库的智能问答
- 自动整合内部文档与外部资源
- 根据查询复杂度动态选择检索策略
客户服务
- Twitch 广告销售:动态检索广告主数据、历史表现、受众分析,生成定制提案
- 智能路由:判断问题复杂度,决定是直接回答还是深度检索
医疗健康
- 整合电子病历与最新医学文献
- 辅助诊断和个性化治疗建议
法律合规
- 合同条款自动审查
- 多文档比对与风险识别
金融分析
- 保险理赔自动处理
- 实时市场分析与风险预测
代码开发(AI 编程助手)
- 根据任务选择最佳搜索策略
- 语义搜索 + 精确匹配的混合使用
- 实时搜索 vs 预构建索引的动态切换
本章学习路径
本模块将系统介绍 Agentic RAG 的完整知识体系:
理论篇
| 章节 | 内容 | 你将学到 |
|---|---|---|
| 13.2 | RAG 演进历程 | 从 Naive RAG 到 Agentic RAG 的技术演进 |
| 13.3 | Agentic 设计模式 | 反思、规划、工具使用、多智能体协作 |
| 13.4 | 工作流模式 | 五种核心工作流模式的设计与应用 |
| 13.5 | 架构分类 | 单智能体、多智能体、层级架构等 |
| 13.6 | 实战应用场景 | 六大行业的真实案例解析 |
实战篇
| 章节 | 内容 | 你将学到 |
|---|---|---|
| 13.7 | LangGraph Agentic RAG 实战 | 使用 LangGraph 构建完整的 Agentic RAG 系统,包括状态管理、节点设计、条件路由、CRAG 和 Self-RAG 实现 |
| 13.8 | Qdrant + LangGraph 实战 | 使用 Qdrant 向量数据库构建生产级 Agentic RAG,包括混合检索、多集合检索、带记忆的对话 |
参考资源
论文
- Agentic Retrieval-Augmented Generation: A Survey on Agentic RAG - Singh et al.
- Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection
- Corrective Retrieval Augmented Generation
官方文档
教程与博客
- Self-Reflective RAG with LangGraph - LangChain Blog
- Building Agentic RAG Systems with LangGraph - Analytics Vidhya
- 为什么 Claude Code 放弃代码索引,使用 50 年前的 grep 技术? - 腾讯云开发者社区
思考题
- 为什么说 Agentic RAG 是 RAG 技术的"必然演进"?
- 在什么场景下,传统 RAG 仍然是更好的选择?什么场景下实时搜索(如 grep)更合适?
- Agentic RAG 的"自主决策"能力可能带来哪些风险?如何缓解?
- 如何设计一个系统,让智能体能够在向量检索、关键词匹配、实时搜索之间动态切换?
- "有时候,遗忘比记忆更强大"——这句话在 AI 系统设计中意味着什么?
核心洞察
"简单的工具活得最久,'健忘'的设计最自由。"
Agentic RAG 的精髓不在于使用最复杂的技术,而在于赋予系统选择的智慧:
- 知道何时需要深度检索,何时简单搜索足够
- 知道何时需要记住状态,何时遗忘反而更好
- 知道何时需要迭代优化,何时一次检索即可
这正是从"工具"到"智能体"的跨越。